
[ComfyMaster62]【完全初心者のための共有ComfyUI入門】無料でAI画像を生成してみよう!

![Cover Image for [ComfyMaster62]【完全初心者のための共有ComfyUI入門】無料でAI画像を生成してみよう!](/assets/2025-04/n8726811ba95b.png)
こんにちは、 Loading tweet component... 文末には #ComfyUI検定試験に向けたクイズも用意しましたので、理解の確認に使ってくださいね! まずは「共有ComfyUI 」について簡単に紹介します。 そもそもComfyUIとは、Stable Diffusionなどの画像生成AIモデルをノードと呼ばれるブロックを繋いで操作できるオープンソースのツールです。高度な画像生成ワークフローを視覚的に組み立てることができ、コード不要で柔軟な画像生成が可能です。 そこで登場するのが「共有ComfyUI」です! 共有ComfyUIは、AICU Japan株式会社が提供する
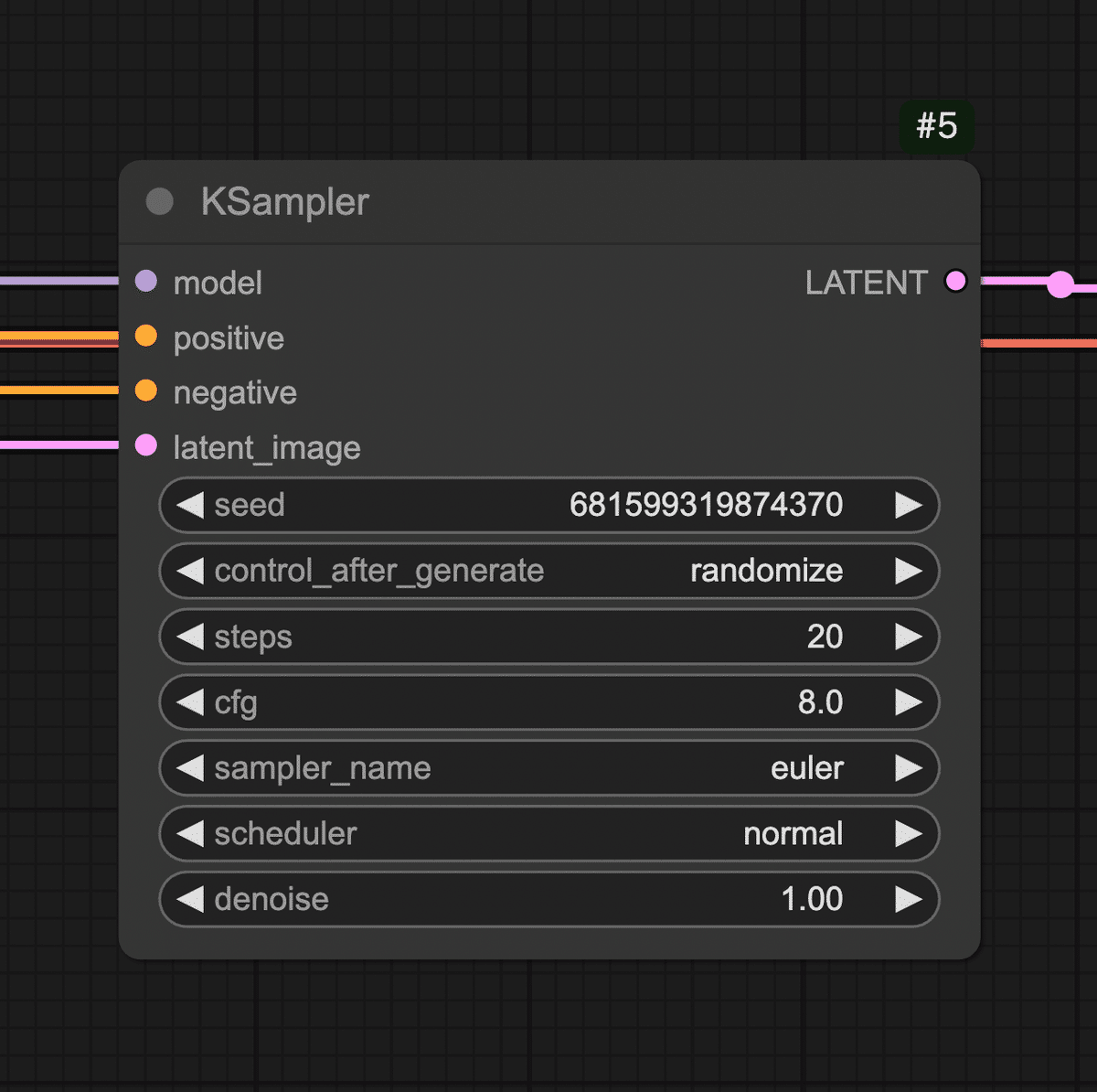
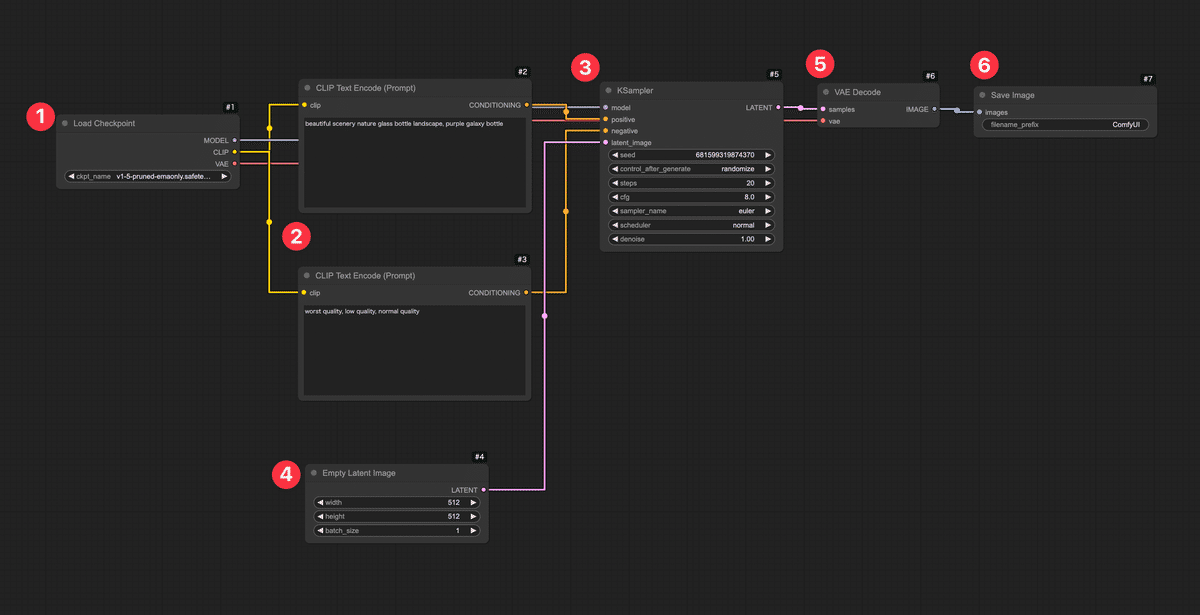
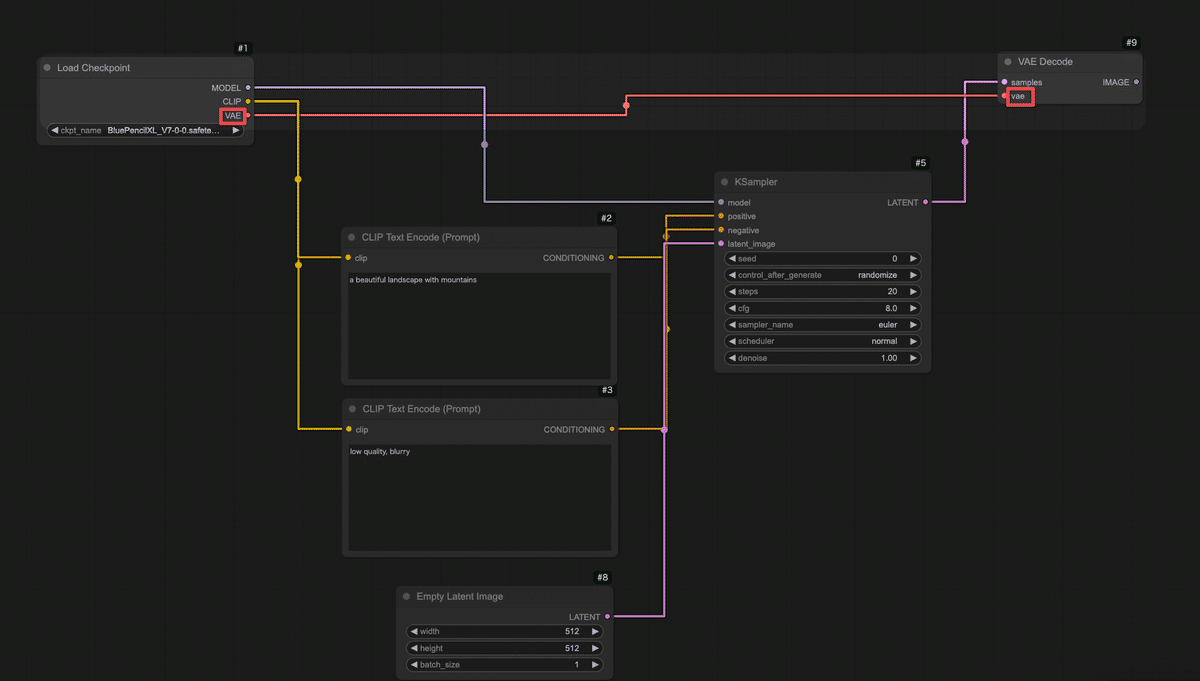
クラウド上のComfyUI環境で、インターネット経由で手軽にComfyUIを利用できます。 主なメリットは、 インストール不要&高性能GPU不要 :ブラウザからアクセスするだけでOK。自分のPCにソフトをインストールしたり、大きなモデルデータを準備したりする必要がありません。手元のPCやタブレット・スマホからでも利用でき、GPUの性能はクラウド側で賄われます。 すぐに使える :わずらわしい環境構築なしに、ComfyUIの機能をすぐ体験できます。難しい設定を飛ばして「触ってみたい!」をすぐ実現できます。 高速な生成 :共有ComfyUIでは高性能なクラウドGPUが割り当てられています。自宅PCでは数十秒〜数分かかる処理も、クラウドならサクサクです! 最新モデルやノードが利用可能 :サービス側であらかじめ人気の画像生成モデル(チェックポイント)や追加機能(カスタムノード)がインストールされています。初心者が一からモデルを探して入れる必要がなく、最初から色々試せる環境が整っています。 みんなで使っているので教えあえる : 分からないことがあればコミュニティで聞くことができます。共有ComfyUIの利用者はAICUの有料記事に自由にアクセスできますし、過去記事を学んだチャットボット「Will」がディープな記事を紹介してくれます。流行りのモデルに出会うことも一人で使うよりも早くアクセスできますね。 https://note.com/aicu/n/n899f35b461db 共有ComfyUIを使うには、まず提供サイトでユーザー登録 (ログイン)が必要です。 ②メールアドレスでログイン/登録:初めて利用する場合はメールアドレスを入力すると、そのアドレス宛に確認コード(ワンタイムパスワード)が届きます。そのコードをサイト上で入力すればログイン完了です。 ③ComfyUIを起動 :ログイン後、「サービス」タブから、1番右の「共有ComfyUI」の「無料お試し期間を始める」をクリックします。 ログインが完了すると、ブラウザ上にComfyUIの操作画面が現れます。 ここではComfyUIの画面構成 と主要な要素(ノード、キャンバス、出力エリアなど)を説明します。 以上がComfyUI画面のおおまかな構成です。 それではいよいよ、画像生成のワークフロー を組んでみます。 Load Checkpoint (モデル読み込みノード) CLIP Text Encode (Prompt) ×2(テキストエンコードノード:ポジティブ用とネガティブ用) KSampler (画像生成サンプラーのコアノード) Empty Latent Image (空の画像キャンバスを用意するノード) VAE Decode (潜在画像を実画像に復元するノード) Preview Image (プレビュー表示ノード) では、順を追ってキャンバスに配置し接続していきましょう。 まずはAIモデル を読み込みます。Stable Diffusion系の画像生成ではモデル(チェックポイント)を読み込まないと何も始まりません。ComfyUIではLoad Checkpointというノードを使ってモデルデータを読み込みます。 モデルを読み込んだだけでは何も起こりません。 次に、2つのCLIPノードを区別します。1つ目 のCLIP Text Encodeノードはポジティブプロンプト用 、2つ目 はネガティブプロンプト用 として使います。それぞれのノードに実際の文を入力しましょう。 ポジティブ用のCLIPノードに、例えば「a beautiful landscape with mountains」(美しい山岳風景)など、お好みのプロンプト文を入力してみてください。日本語で入力できるモデルもありますが、基本は英語 が無難です。簡単な単語の並びでも大丈夫です。 ネガティブ用のCLIPノードには、「low quality, blurry」など出力画像で避けたい要素 を入力します。 続いて、実際に画像(正確には画像の元になるデータ)を生成する処理を担うノードを追加します。Stable Diffusionではサンプリングと呼ばれるプロセスでAIが徐々に画像を描き出します。そのコア部分を受け持つのがKSampler というノードです。 KSamplerノードの入力端子を確認します。「model」(モデル本体)、「positive」(ポジティブプロンプト条件)、「negative」(ネガティブプロンプト条件)、「latent_image」(潜在画像)などの入力があります。 まずmodel 入力に、Load CheckpointノードのMODEL出力 を繋ぎます。Load Checkpointノードから伸びているMODEL という端子からドラッグし、KSamplerノードのmodel という入力端子にドロップしてください。これでKSamplerはStable Diffusionモデル本体(UNetなど)にアクセスできます。 次にpositive 入力に、ポジティブ用CLIPノードの出力 を繋ぎます。同様に、ポジティブCLIPノードの右側出力から線をドラッグし、KSamplerのpositive入力へ。negative 入力にもネガティブ用CLIPノードから線を繋ぎます。これでテキストで与えた指示(プロンプト)がKSamplerに渡るようになります。 💡KSamplerノードには各種パラメータ (サンプルステップ数、CFGスケール、シード値など)の設定項目もあります。 今回はデフォルト値で問題ありませんが、興味があればノードのプロパティを確認してみましょう。「Steps」(ステップ数:生成の繰り返し回数)や「Seed」(乱数シード値:画像のランダム性を決める番号)などがあります。 次に、生成する画像の「下地」となるものを用意します。 ここまででKSamplerノードは潜在画像(latent image)形式で結果を出力する準備が整いました。 接続 samples入力に、KSamplerノードの出力(潜在画像)を繋げます。KSamplerの右側に「LATENT」と書かれた出力端子があるので、そこからVAE Decodeノードのlatent入力へドラッグしてください。これでKSamplerが生成した潜在画像データがVAE Decodeに渡ります。 VAE入力には、Load CheckpointノードのVAE出力 を繋ぎます。実はStable DiffusionのモデルデータにはVAEが含まれていることが多く、Load Checkpointノードはそれも読み込んで提供しています。Load Checkpointノードの右側に「VAE」と書かれた出力端子があるので、そこから線を出してVAE DecodeノードのVAE入力に繋いでください。 これで、潜在画像+VAEモデルが揃い、VAE Decodeノードが人間の目に見える画像データを生成できる状態になりました。 最後に、生成された画像を実際に画面に表示して確認するためのノードを繋ぎます。 Preview Imageノードには特別な設定はありません。 お疲れさまでした! ざっとおさらいすると、「Load Checkpoint」→「CLIPエンコード(positive/negative)」→「KSampler」→「Empty
Latent」→「VAE Decode」→「Preview Image」という流れです。 ノードごとの配置は、ずれていても構いませんが、必ず上記の通り全ての接続が繋がっていること を確認してください。 ワークフローの構築ができたら、いよいよ実行 してみましょう。 あとはQueueボタンを押すのみ! ボタンを押すと即座に画像生成がスタートします。共有ComfyUIでは進行状況のログが左側のバーにある「キュー」にて確認できます。 💡万が一、数十秒経っても変化がない場合、接続ミスなどが考えられます。エラー表示や最終的なノードワークフローがこれまでの手順とあっているかご確認ください。 処理が完了すると、キャンバス上のPreview Imageノード内でも実際に生成された画像が表示されます!おそらく小さなサムネイルとしてノード内に出るので、確認してみてください。ノードをクリックすると拡大表示されたり、詳細を確認できる場合もあります。 正常に実行できていれば、指定したプロンプトに基づく画像が1枚生成され、プレビューに表示されたはずです。 ComfyUIでPreview Imageノードに接続して表示された画像は、一時的にメモリ上に存在しているものです。つまり「画面に見えているだけ」の状態で、まだファイルとして保存されたわけではありません。 プレビューに表示された画像を右クリックして「Save Image」をクリックしましょう。 ここまで、共有ComfyUIを使ってテキストから画像を1枚生成する手順 を解説しました。 最後にここまで作ったノードワークフロー内で何が行われていたのか、簡単に振り返ってみましょう。 Load Checkpoint :選択したStable Diffusionモデル(チェックポイント)を読み込み、そのモデルの各構成を後続ノードに提供しました。 CLIP Text Encode (Prompt) :入力したテキスト(プロンプト)をモデル付属のCLIPエンコーダーで数値ベクトルに変換しました。ポジティブ・ネガティブ2つに分け、それぞれの条件を用意しました。 KSampler :読み込んだモデルに対して、ランダムなノイズ画像から徐々に絵を生成する拡散モデルの過程を実行しました。CLIPで得たテキストのベクトル情報(「山の風景を描いて!」という指示)を参照しつつ、Empty Latent Imageで渡された初期ノイズを何ステップかかけて洗練し、画像を描き出しています。 Empty Latent Image :指定サイズの初期画像(ノイズキャンバス)を提供しました。KSamplerはこれを出発点にして画像生成を行いました。シード値が同じなら毎回同じノイズが生成され、再現性が高くなります。一方、シードが違えば別のノイズになるため、出力画像も変化します!これはChatGPT等ではできないテクニックです。 VAE Decode :KSamplerが生成した画像データを、元の画像空間にデコード(復元)しました。人間には判読できなかった潜在表現が、このノードを通すことで普通の画像(ピクセルデータ)に戻ります。 Preview Image :得られた最終画像をキャンバス上に表示しました。 この一連の流れにより、テキストから画像が生成されます。 初心者のうちは多少つまずくこともありますが、落ち着いて原因を切り分けていけば必ず解決できます。 本記事は共有ComfyUI入門の第1歩でした。 a) インストール不要で、ブラウザからアクセスできる。 b) 高性能GPUが不要で、クラウド側のGPU性能を利用できる。 c) 最新の画像生成モデルやカスタムノードが事前にインストールされている。 d) 自分のPCにインストールするため、生成速度が速い。 a) キャンバスは、ノードを配置する画面全体の黒地の領域である。 b) ノードは、キャンバス上で右クリックすることで追加できる。 c) プロパティは、ノード間を繋ぐ線の太さを調整する設定項目である。 d) 線(リンク)は、入力端子から出力端子へドラッグすることで接続できる。 a) Load Checkpoint ノードは、Stable Diffusionモデルを読み込む。 b) CLIP Text Encode (Prompt) ノードは、テキストをAIが扱いやすいベクトルにエンコードする。 c) KSampler ノードは、RGB画像に対してノイズを除去して画像を描き出す。 d) VAE Decode ノードは、潜在画像を実画像に復元する。 a) ワークフローを構築後、保存ボタンを押して画像生成を開始する。 b) 画面下の「Queue」ボタンをクリックして、ワークフローを実行する。 c) 生成された画像は、自動的にPCのデスクトップに保存される。 d) 画像の生成が完了したら、ターミナルから保存コマンドを実行する。 次回以降の記事でも、今回のワークフローを発展させてComfyUIのさまざまな可能性に挑戦してみる予定です。 最後までお読みいただきありがとうございました。 https://note.com/aicu/n/n4d8df05ea16f https://note.com/aicu/n/nd040234e5124 この記事の続きはこちらから https://note.com/aicu/n/n8726811ba95b Originally published at note.com/aicu on Apr 11, 2025.
本記事では、これからComfyUI を触ってみたい超初心者の方に向けて、クラウド上で使える「共有ComfyUI」を無料でお試しして、AI画像を出力するまでの手順を丁寧に解説します。難しい専門用語はできるだけ噛み砕き、ステップ・バイ・ステップで進めていきますのでご安心ください。
実際に手を動かしながら読み進めて、AI画像生成の第一歩を踏み出しましょう!
1. 共有ComfyUIとは?クラウドで使うメリット
ただし、通常ComfyUIを使うには自分のPCに環境を構築し、大きなAIモデルを扱うための高性能GPUも必要になります。
初心者にとってこれらの準備はハードルが高いですよね ><
共有ComfyUIの利用開始(登録)の概要
といっても難しい手続きはなく、メールアドレスさえあればすぐに始められます!
①公式サイトにアクセス:ブラウザで共有ComfyUIのサイトにアクセスします。
続いてお支払い画面が表示されるので、クレジットカード情報の入力、プランポリシーへの同意を行い、「無料お試し期間を開始」をクリックしてください。
2. ComfyUIの画面構成を知ろう
初めて見る画面は少し独特かもしれませんが、各部分の役割を押さえれば怖くありません。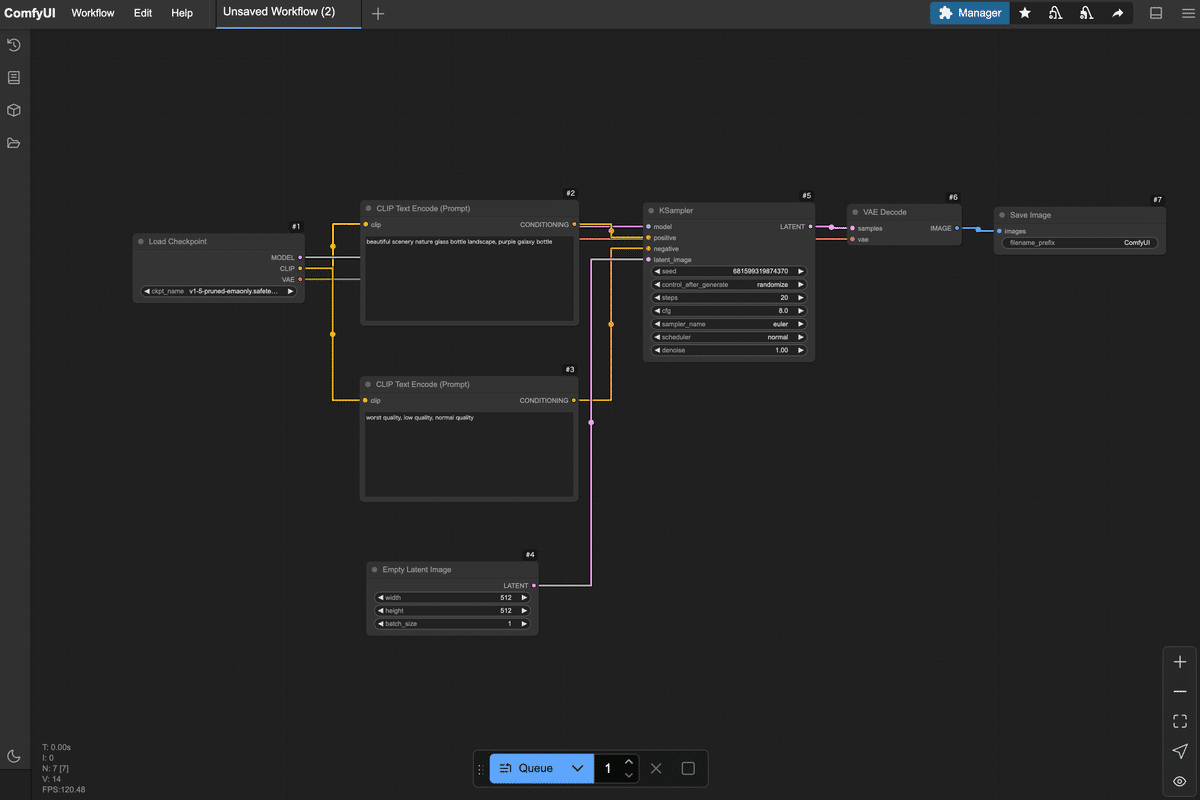
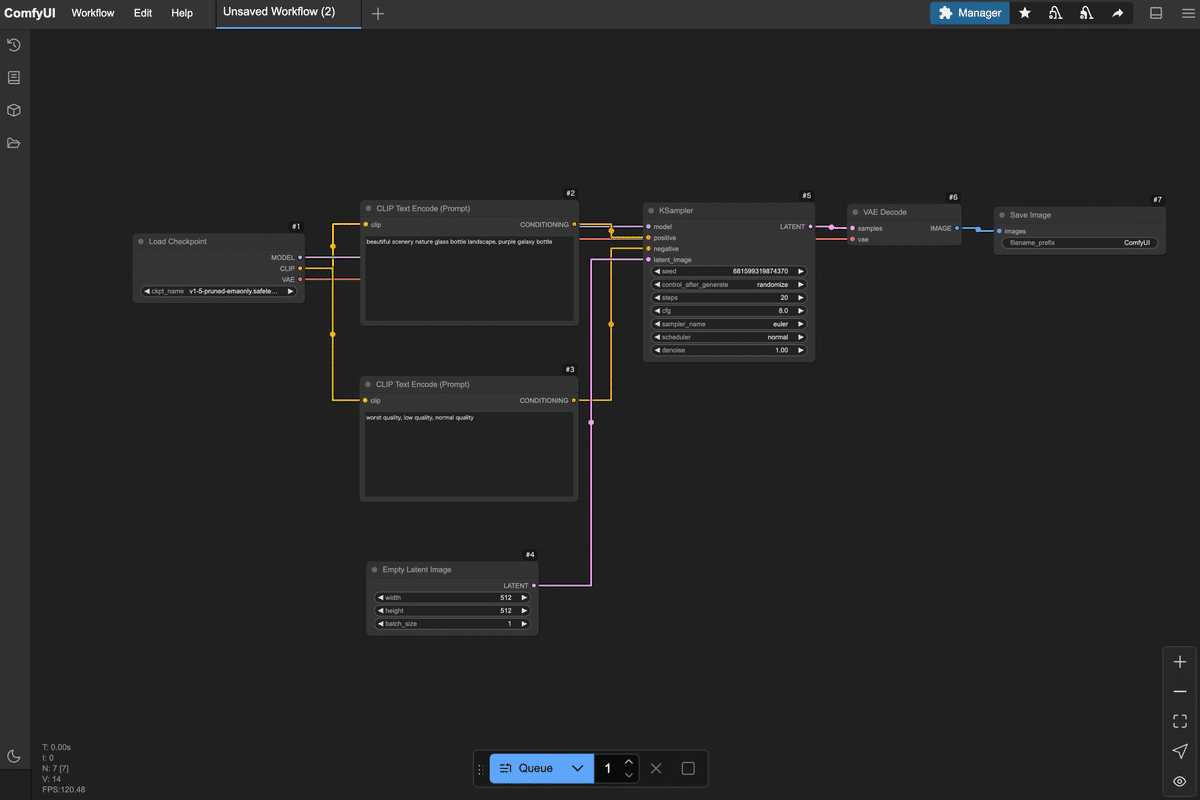
最初は空っぽのキャンバスに何をしていいか戸惑うかもしれませんが、次章から実際にノードを置いていくので一緒にやってみましょう!3. 最小限のノードで画像生成ワークフローを作ってみよう
ここでは「テキスト(プロンプト)から1枚の画像を生成する」ために必要な最小限のノードを追加し、順番に繋げていきます。**
難しく感じるかもしれませんが、ノードは基本的に上流から下流へ繋げていくだけ です。一緒にやってみましょう!
今回は以下の6種類のノードを使います(名前は英語ですが順に説明します):
Step 1: モデルの読み込み(Load Checkpointノード)
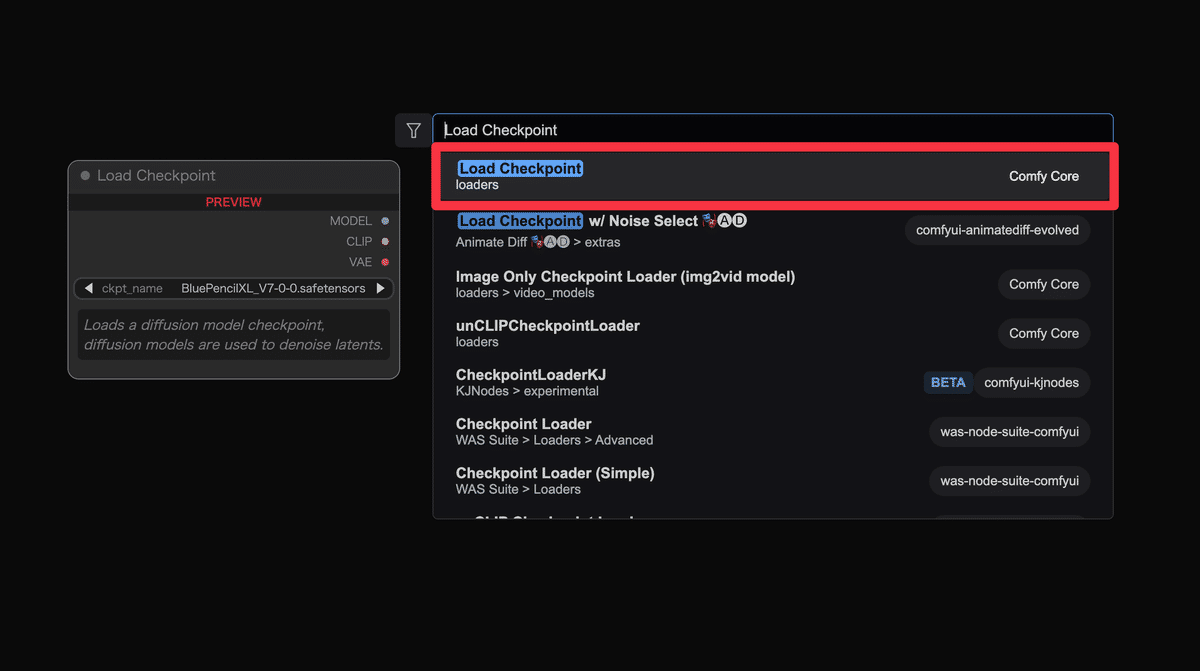
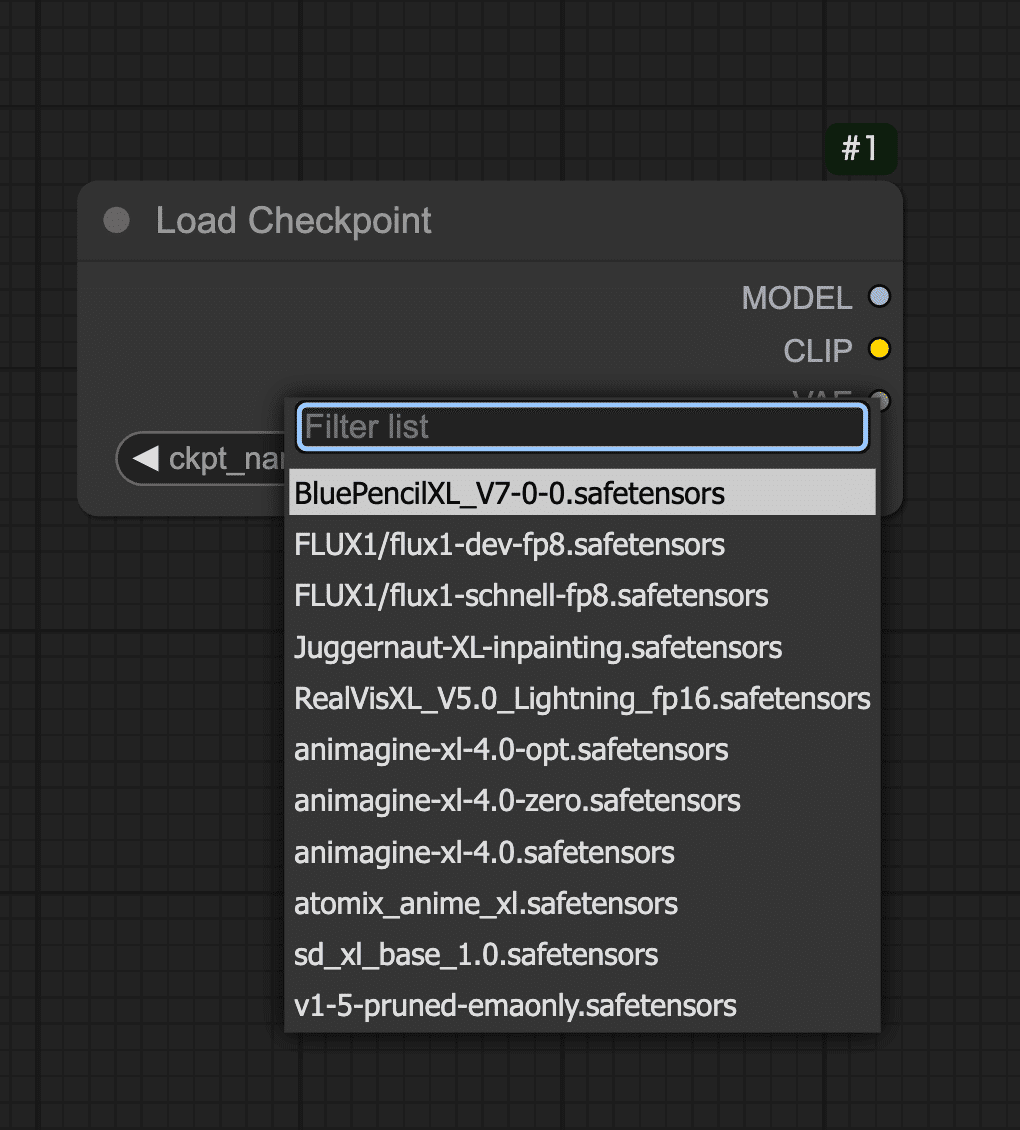
Step 2: プロンプト入力ノードを追加(CLIP Text Encode)
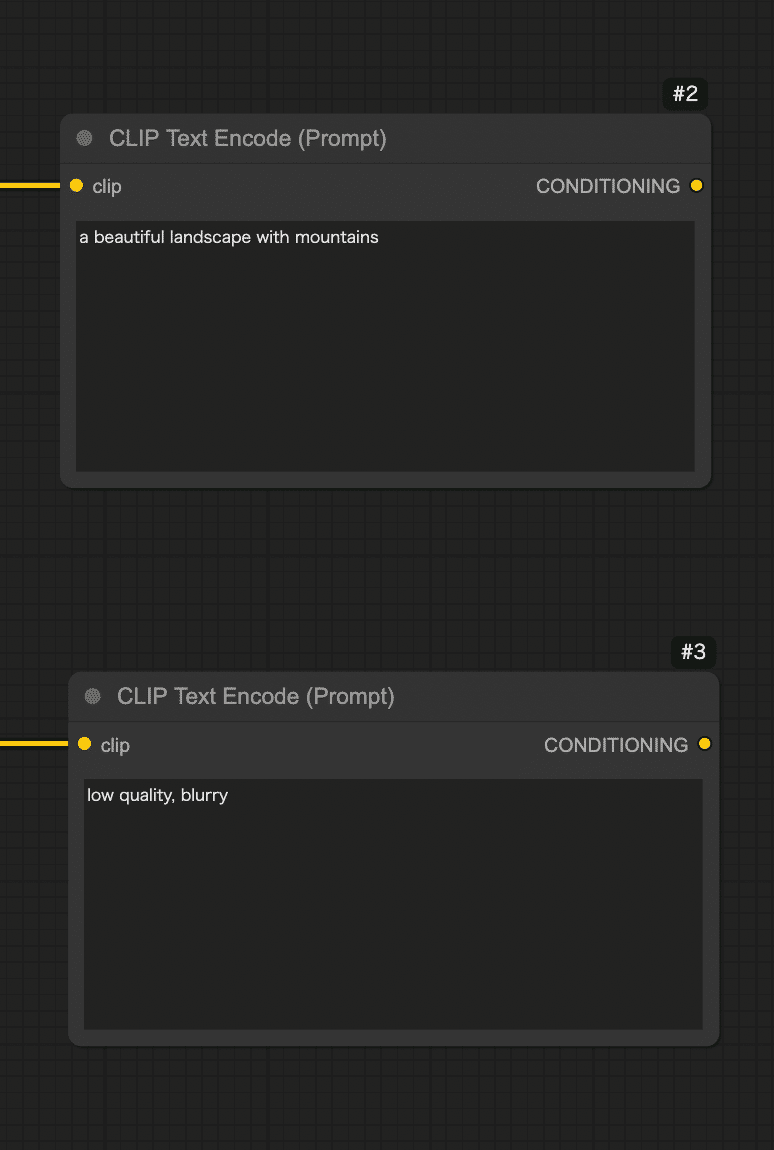
次に画像の内容を指示するテキスト(プロンプト)を入力するノード を用意しましょう。Stable Diffusionでは「ポジティブプロンプト」と「ネガティブプロンプト」の2種類のテキストが指定できます。ポジティブプロンプトは「出力画像に積極的に反映したい要素」、ネガティブプロンプトは「除外したい要素(出力してほしくない特徴)」です。
ComfyUIではこれらを CLIP Text Encode (Prompt) というノードで実現します。
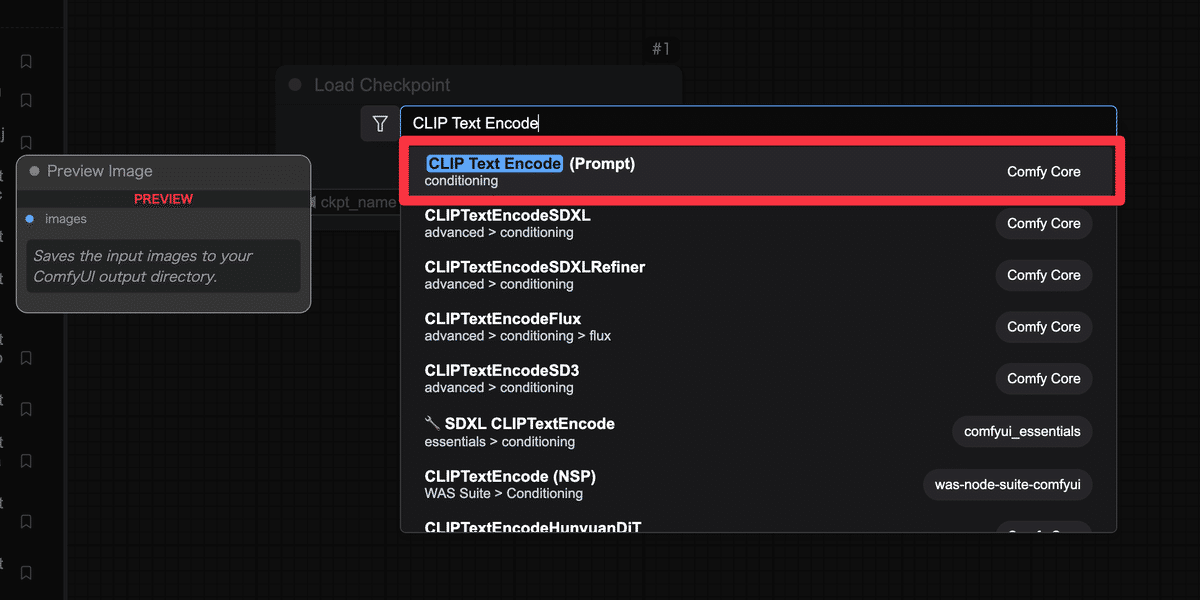
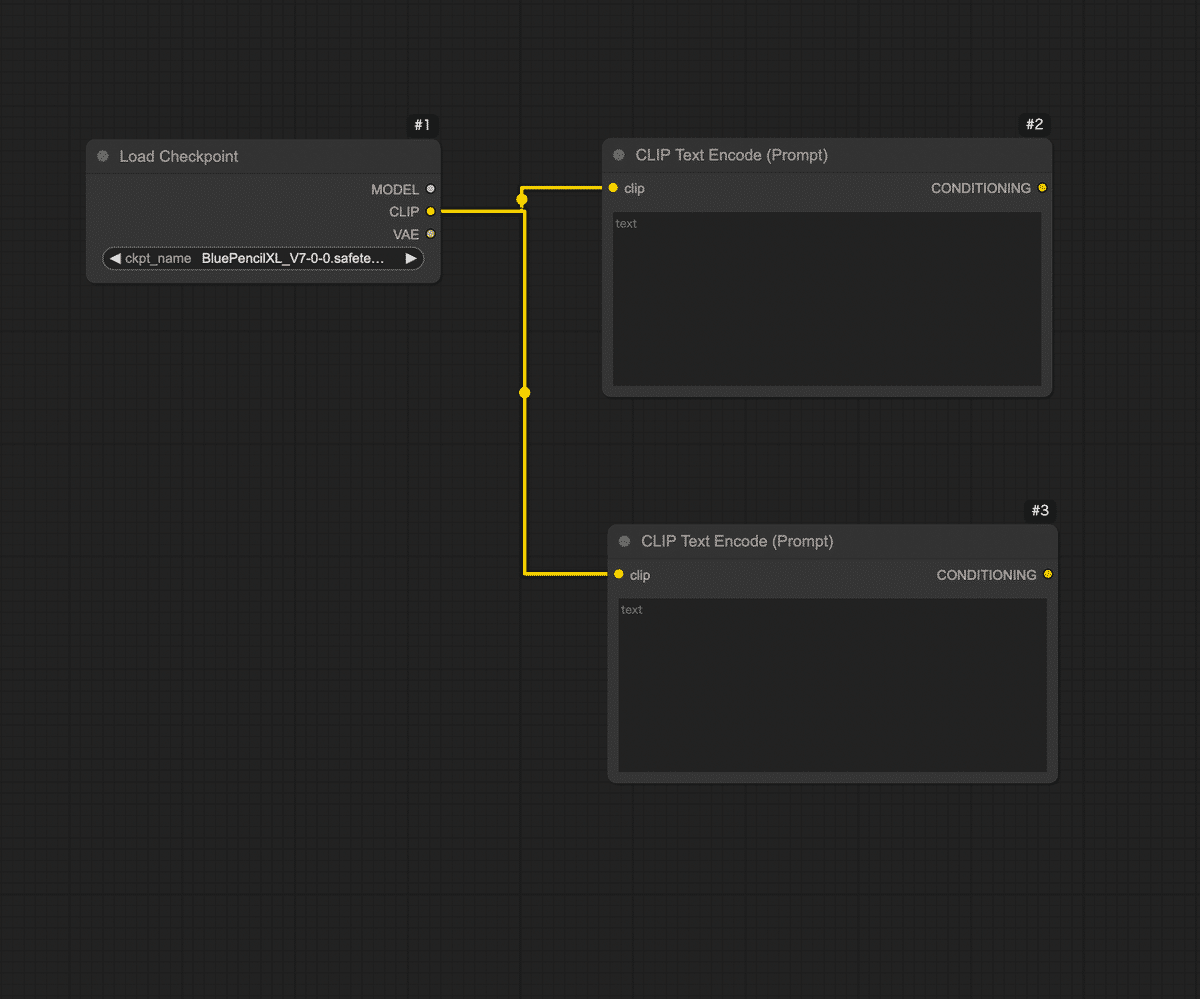
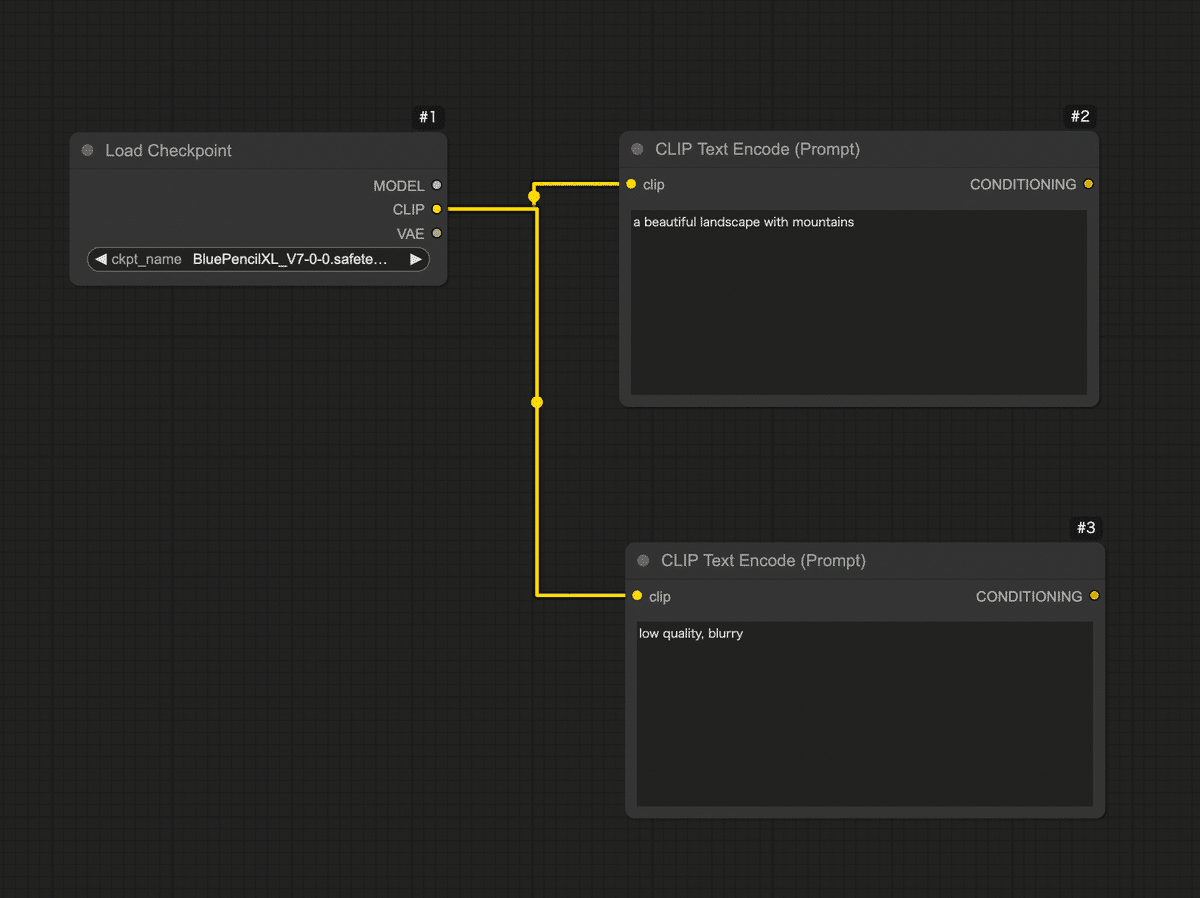
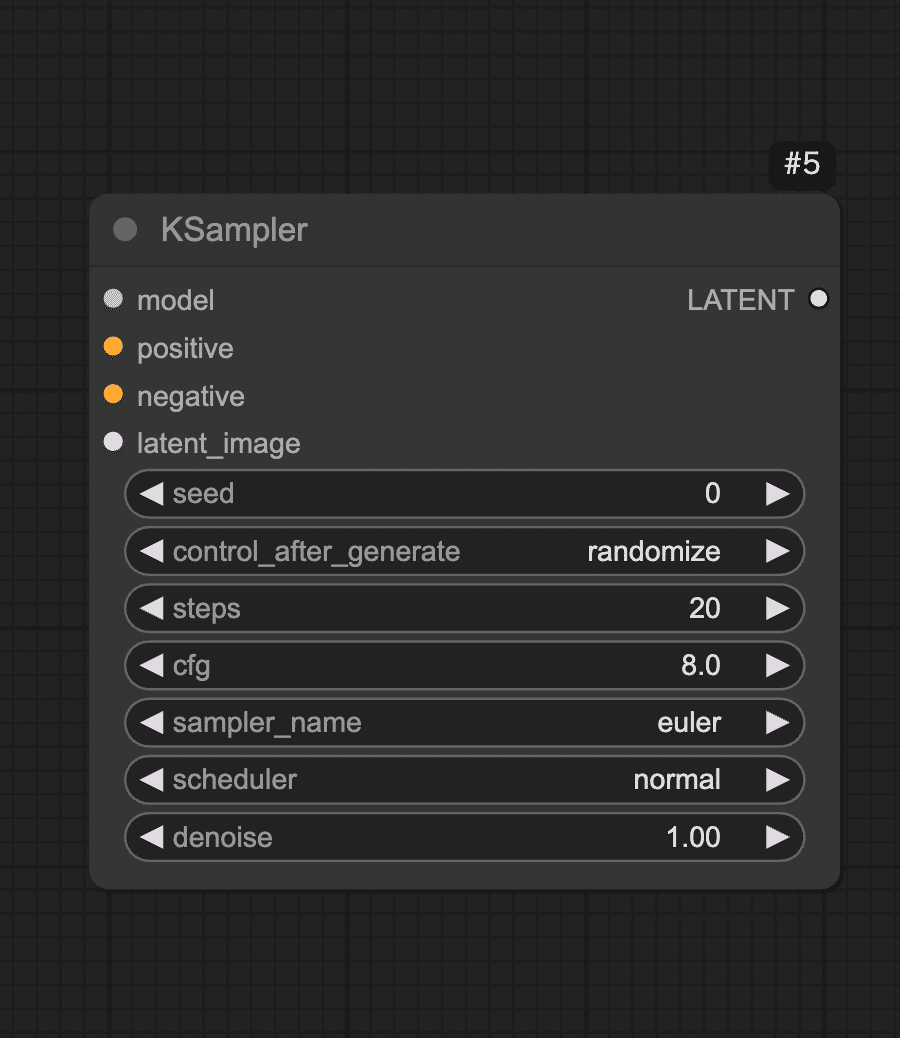
Step 3: 画像生成の核となるサンプラーノード(KSampler)を配置
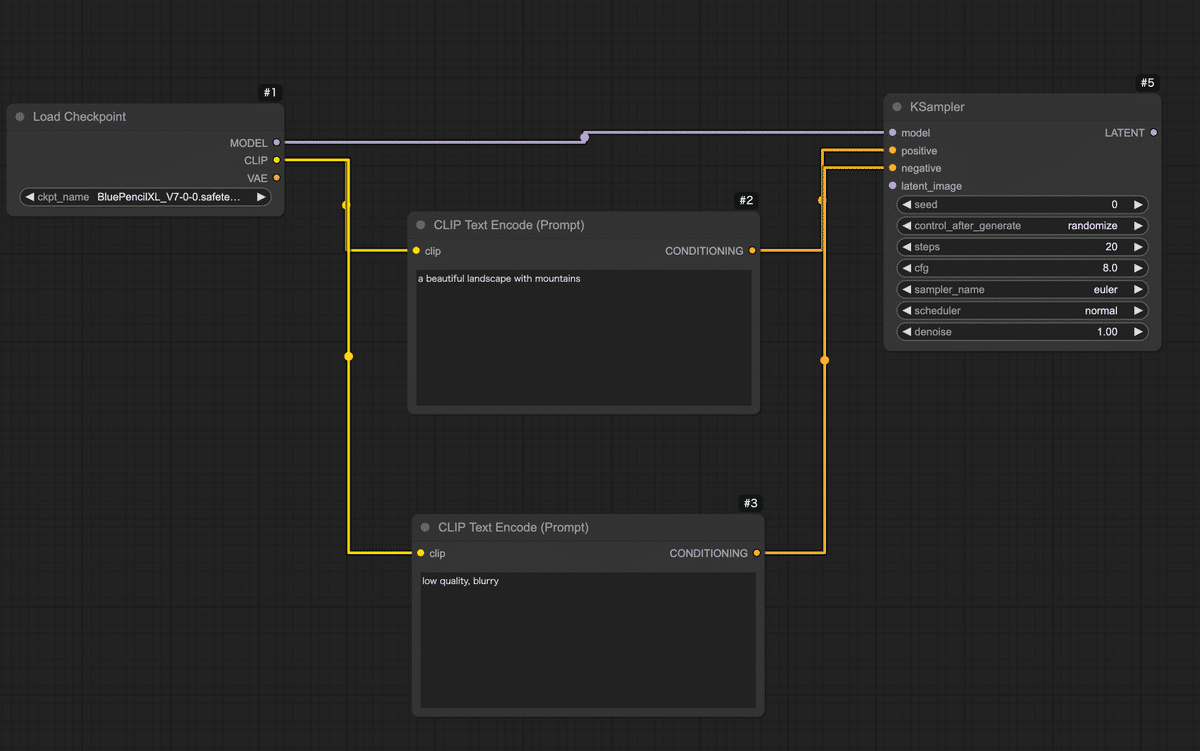
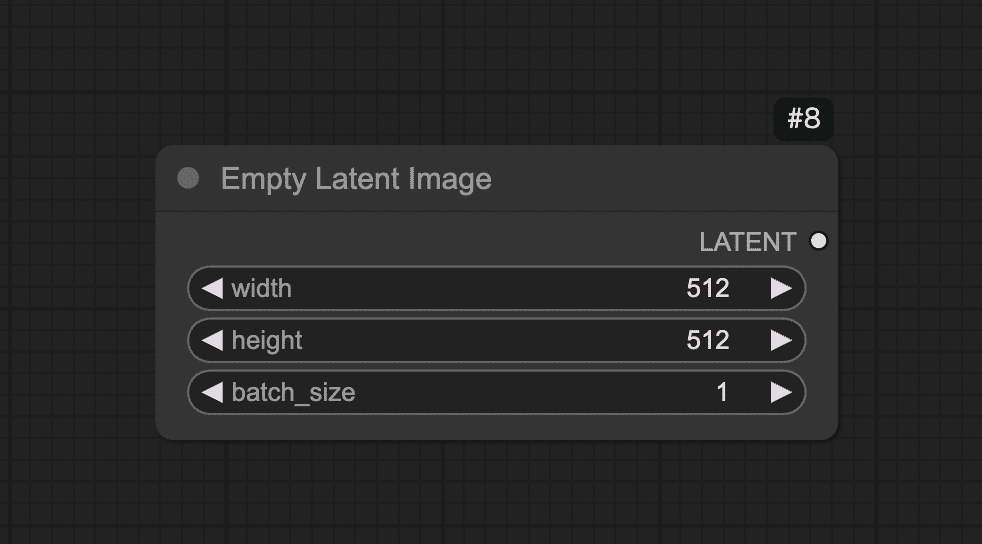
Step 4: 空の画像キャンバスを用意する(Empty Latent Imageノード)
AIは何もないところからいきなり絵を描くのではなく、まずランダムなノイズ画像(塗り潰しキャンバス)を用意し、そこから徐々に絵を浮かび上がらせていく仕組みになっています。
ComfyUIではこの「最初のノイズキャンバス」をEmpty Latent Imageノードで作ります。
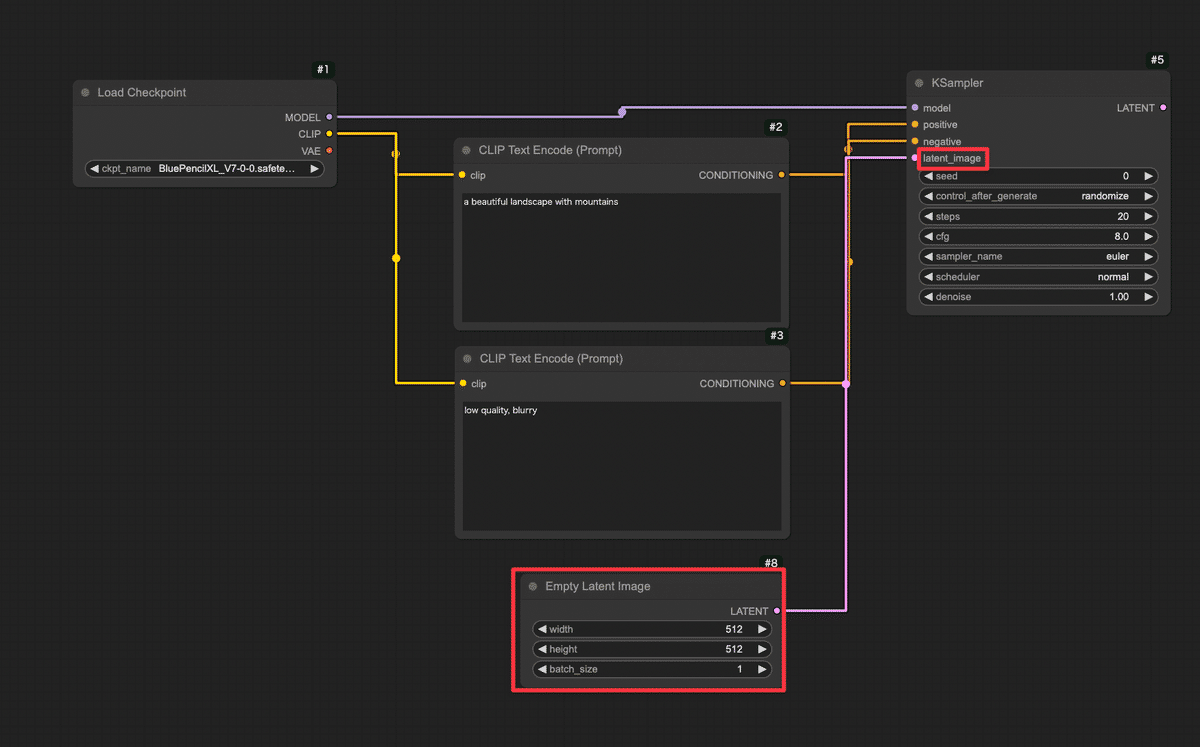
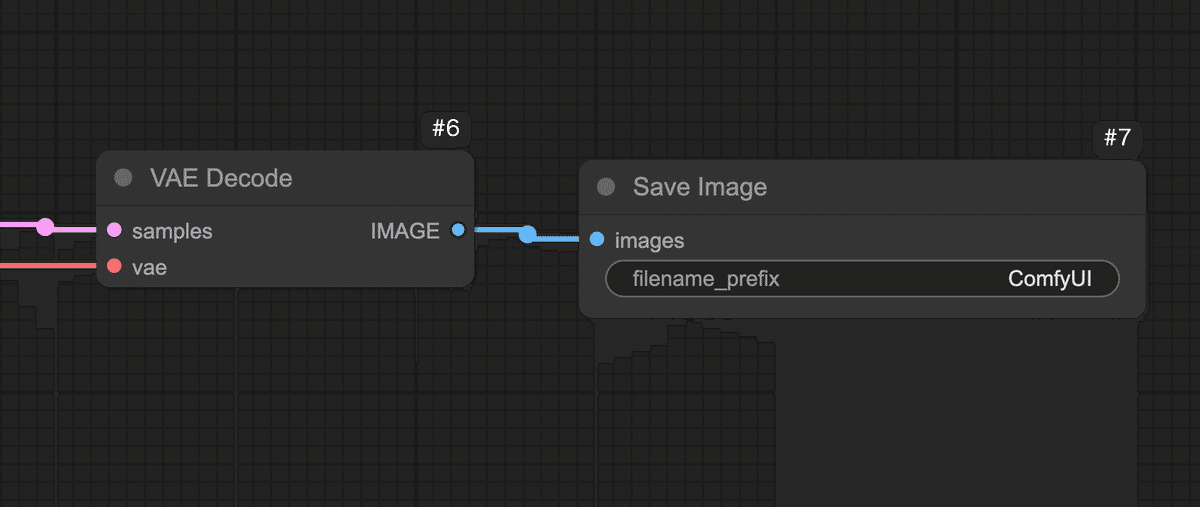
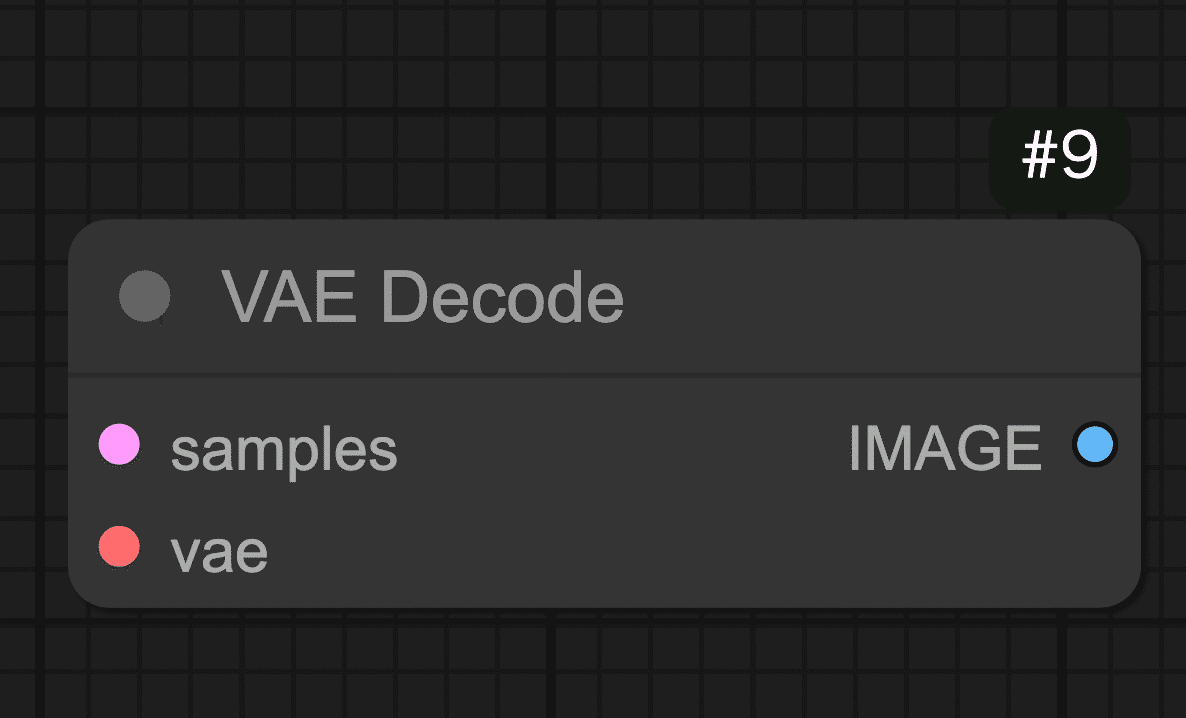
Step 5: 潜在画像を実画像に復元する(VAE Decodeノード)
しかし、そのままでは人間が見てもノイズのようなデータです。
そこで、AIが内部で使う潜在表現を人間が見られる実際の画像(ピクセルデータ)に変換する必要があります。
それを行うのがVAE Decode ノードです。
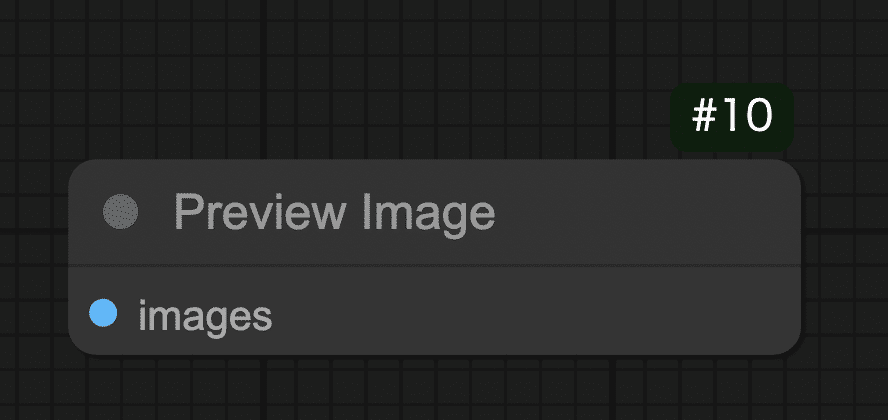
Step 6: プレビューノードを繋いで画像を表示する(Preview Imageノード)
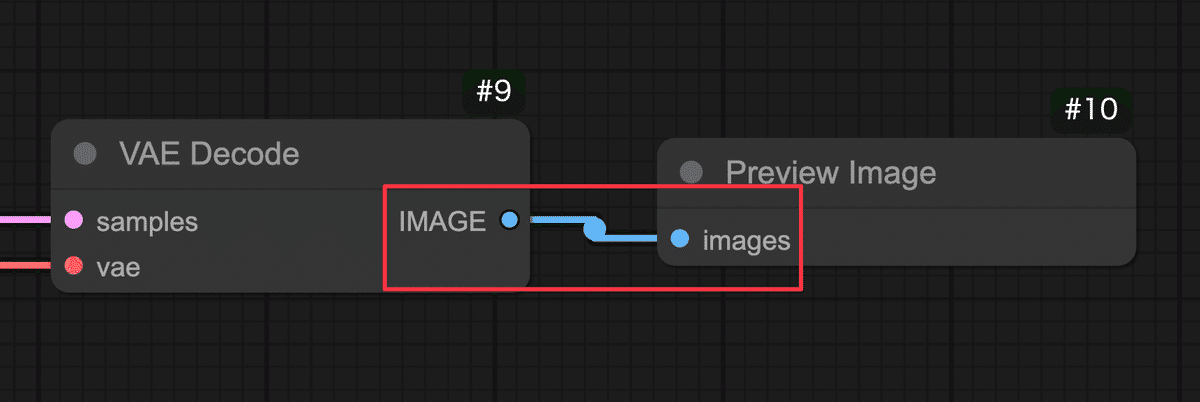
以上で、画像生成のための基本的なノード接続は完了です!
今キャンバス上には、モデル読み込みからテキストエンコード、サンプリング、VAE復元、プレビューまで一直線につながった一連のノードが並んでいるはずです。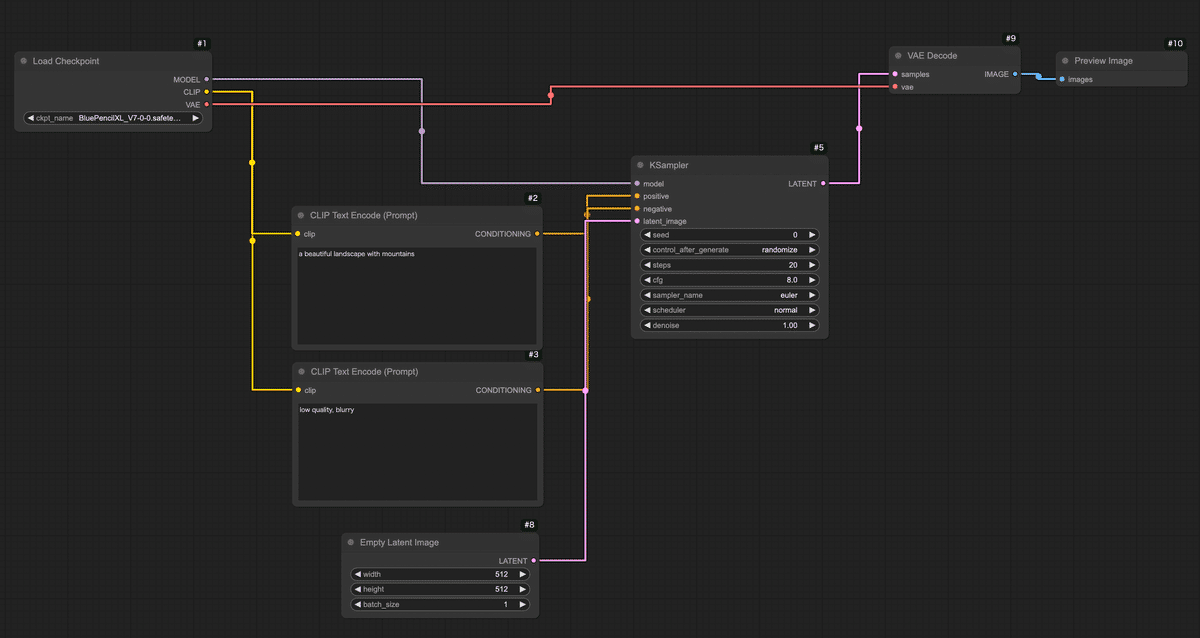
これで画像生成の下準備は整いました!4. いざ実行!画像を生成してみよう(Queueボタンと生成の流れ)
共有ComfyUIでは、準備が整ったらQueue ボタンを押すことで現在のワークフローを実行し、画像生成を開始します。
生成の実行手順
画面下の「Queue」と書かれたボタンをクリックしてください。
すると、現在キャンバス上にある一連のノードが順番に処理を開始します。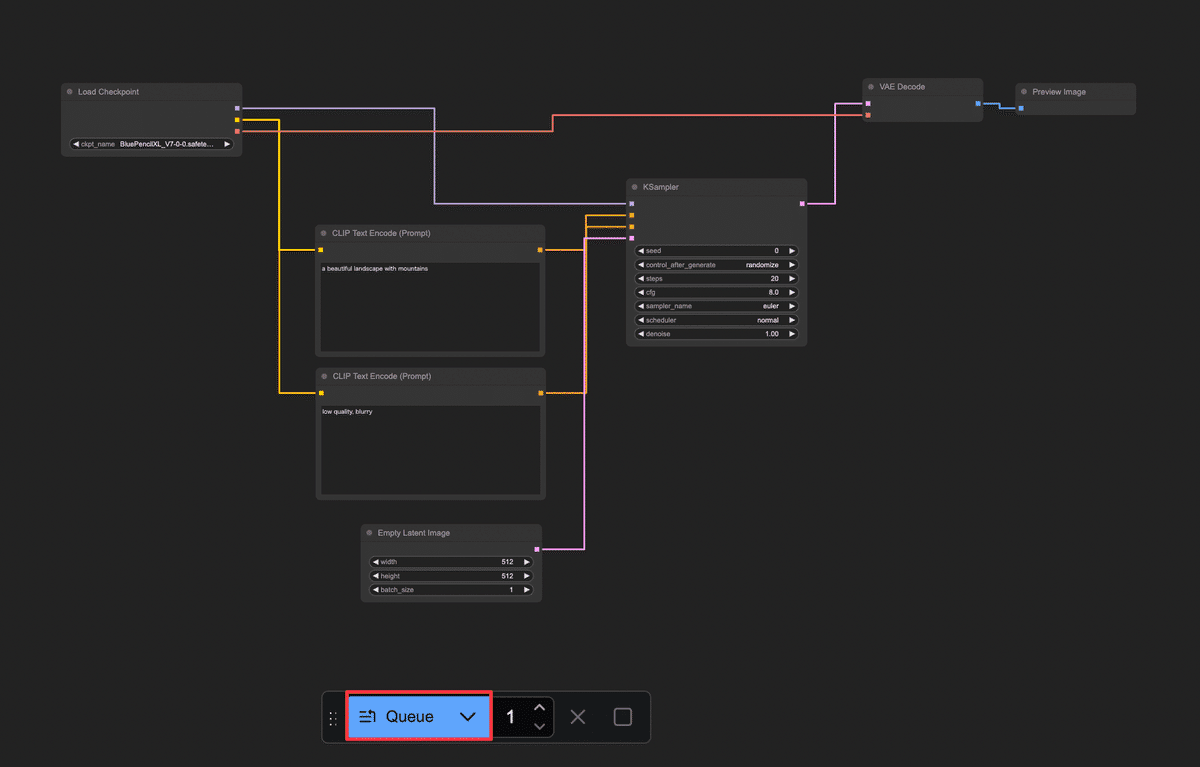
キューを確認すると画像が処理されて完成していく様子が確認できます。
通常数秒〜十数秒 で完了します。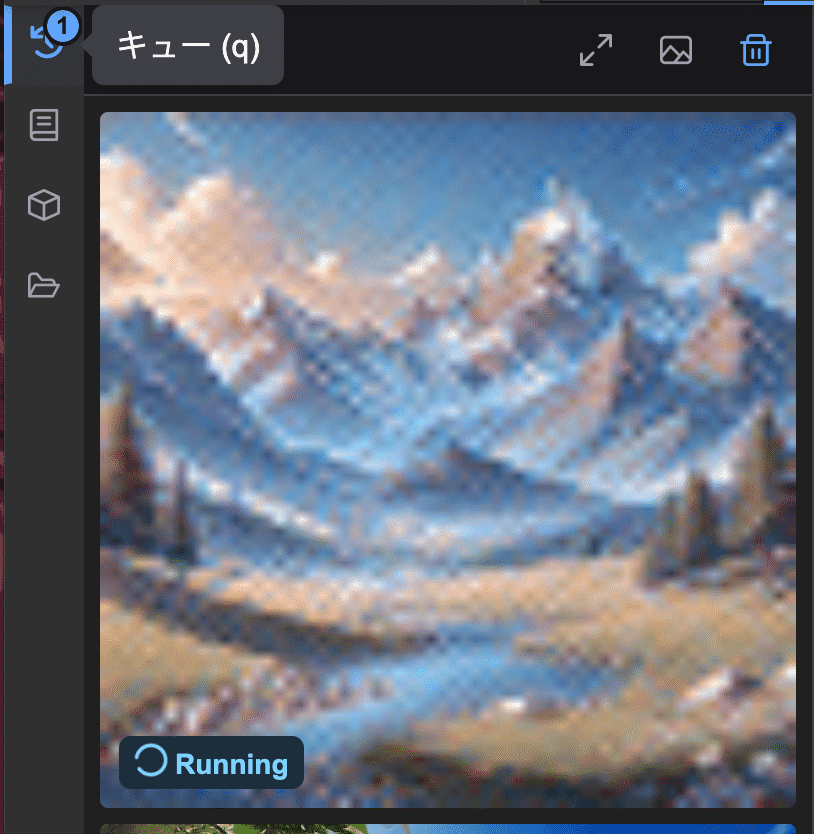
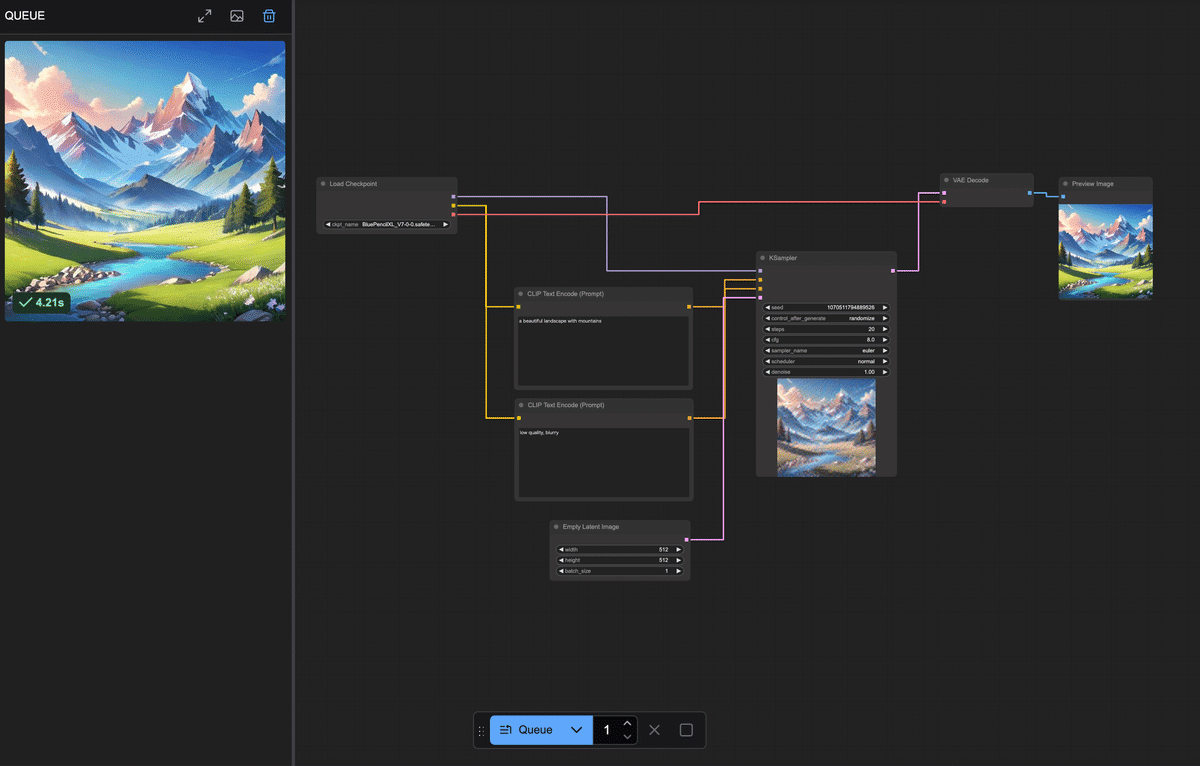
今回はポジティブプロンプトに「a beautiful landscape with
mountains」を入れたので、美しい山の風景画像が得られていることでしょう!
5. 出力画像を保存しよう
したがって、大事な画像はユーザーが保存操作を行う必要があります。画像を保存する方法
これで画像ファイルとして任意の場所にダウンロードされました。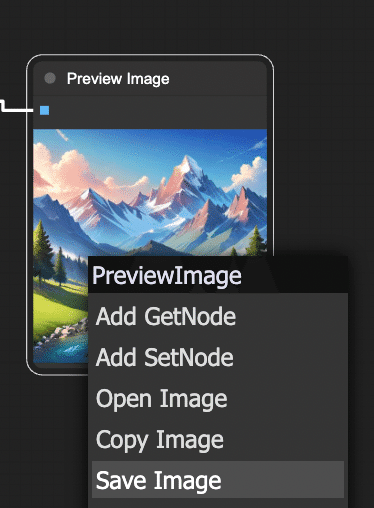
6. まとめ
環境登録から始まり、ComfyUIの画面説明、ノードを組んで実行、そして出力画像の保存まで、一連の流れを体験できたと思います。
最初はノードや接続に戸惑うかもしれませんが、実際に動かしてみると「思ったより簡単かも!」と感じられたのではないでしょうか。生成処理の流れをおさらい
「プロンプトをAIに理解させて、AIモデルでノイズから画像を描き、最後に人間向けの画像に変換して見せている」と捉えていただければOKです!
それでも不明な点があれば、サービス提供元の AICU.jp コミュニティサイトの掲示板で質問してみるのが良いでしょう。ComfyUI 検定試験 問題「共有ComfyUI 入門」
Q1: 共有ComfyUI の主なメリットとして、誤っているものはどれですか?
Q2: ComfyUI の画面構成要素に関する説明として、正しいものはどれですか?
Q3: 画像生成ワークフローにおける各ノードの役割について、誤っているものはどれですか?
Q4: 共有ComfyUI で画像を生成する際の手順として、正しいものはどれですか?
正解と解説は、メンバーシップ向けペイウォールの向こう側に記載させていただきます。
さらに実践的でワクワクする内容をお届け予定ですので、お楽しみに!
共有ComfyUIでのAI画像生成をぜひ楽しんでくださいね✨
またお会いしましょう!