
ComfyUIにGPT-Image-1 APIノード(ベータ版)、オープンソースで有料サービスを実装…!?


OpenAIが2025年4月24日に発表した最新の画像生成API「GPT-Image-1 」(ChatGPT 4oの画像モデルを支えたモデル)が、ComfyUIのネイティブAPIノード(ベータ版) として利用可能になりました。
これにより、面倒なAPIキー設定なしで、最先端の生成技術をノードグラフ上で直接利用できるようになりました。
Loading tweet component... Loading tweet component... Comfy Orgの公式ブログ Jo Zhangによると ついに、AGI(All Ghibli Images)があなたのComfyUIにもやってきます! この機能は現在ベータテスト中で、早期体験を希望するユーザーに開放されています! まずはGPT-Image-1の特徴を確認しておきましょう。 OpenAIのマルチモーダルフラッグシップモデル 対応画像サイズ: ・スクエア(1024×1024) 画質オプション:Low / Medium / High 透過背景やマスク編集にも対応(ComfyUI内で可能) ① ComfyUIを最新版にアップデート ② ログイン Settings → User → Login からComfy Orgアカウントでログイン(新規作成も可能)。 ③ クレジットをチャージ Settings → Credits → Buy Credits からプリペイド形式で購入。使った分だけ消費され、追加料金の心配はありません。 ④「OpenAI GPT Image 1」ノードを追加 ⑤ Canvasに配置して実行! ※画像入力やマスク編集には「Load Image」ノードを追加してください。 ※注意:OpenAIの有料APIを通して動作するため、クレジット購入が必要です。API統合はオプション機能であり、ComfyUI本体は今後も完全オープンソース・ローカル無料利用が基本
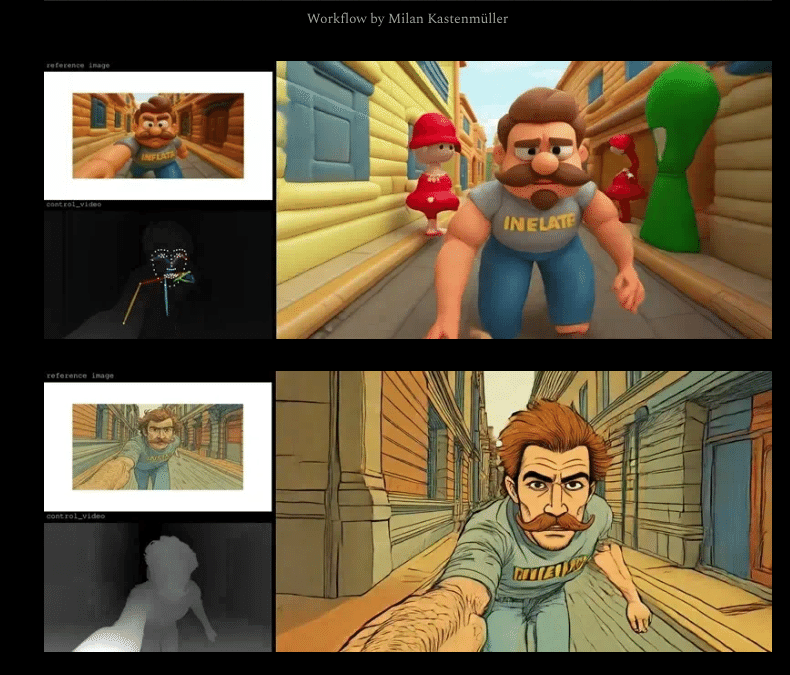
とのことです。 GPT-Image-1は、ローカルモデルと組み合わせることでさらに威力を発揮します。 例えば、 OpenAIの画像生成APIでリスタイルした画像を作成 その画像を、ComfyUI Wan2.1 Image-to-Video やVACEコントロールビデオ生成ワークフロー に流し込むことも可能です。 GPT Image 1 + Wan2.1 I2Vワークフロー テキスト入力:$5/100万トークン 画像入力:$10/100万トークン 画像出力:$40/100万トークン ※すべてOpenAI公式価格に準拠 今回のGPT-Image-1対応は、ComfyUIの「外部モデル対応」戦略の第一歩です。今後もさまざまな外部モデルを統合し、ComfyUIをユニバーサルな生成AIインターフェースへと進化させて行くとのこと。 以上、Jo Zhangによる2025年4月24日の公式ブログに基づくAICU翻訳でした!ぜひ、皆さんのフィードバックや活用例もお寄せください!あなたの声が、ComfyUIの未来を形作ります。 https://blog.comfy.org/p/comfyui-now-supports-gpt-image-1 Originally published at note.com/aicu on Apr 29, 2025.
GPT-Image-1の特徴
・縦長(1024×1536)
・横長(1536×1024)
・オートモード
使い方
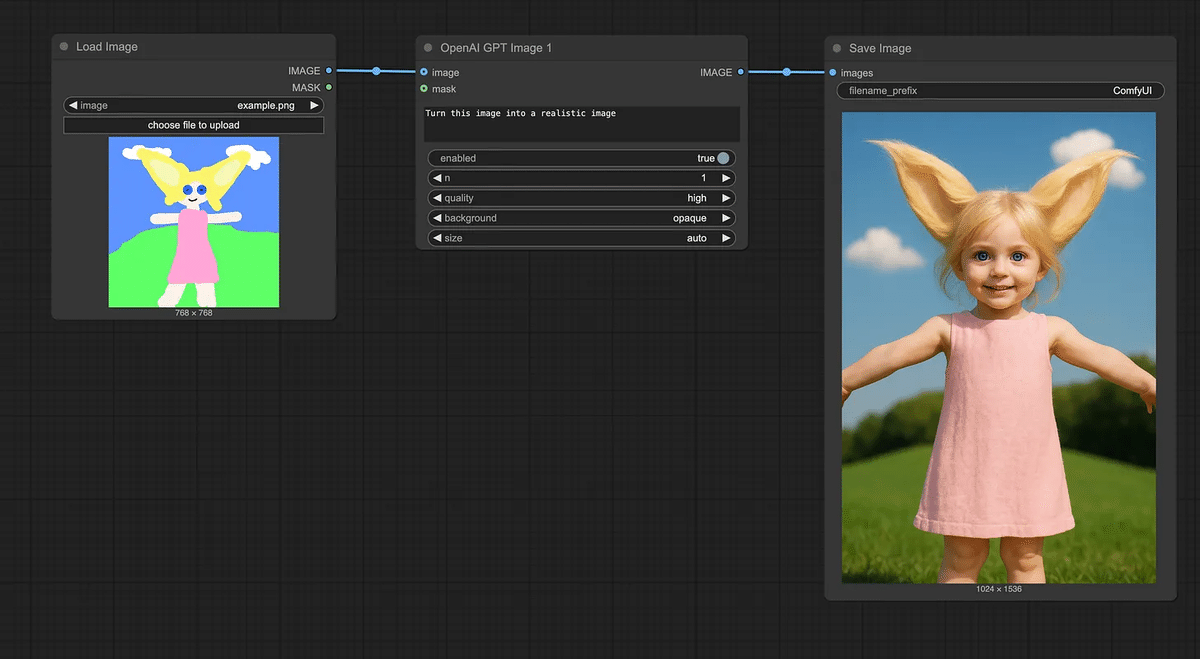
ワークフロー紹介
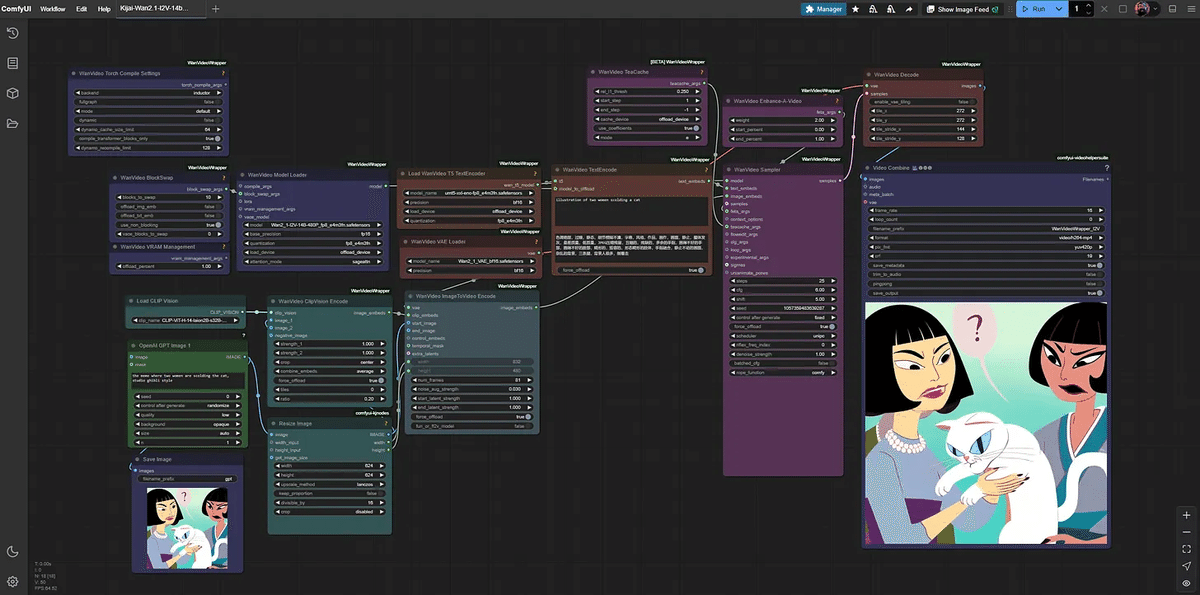
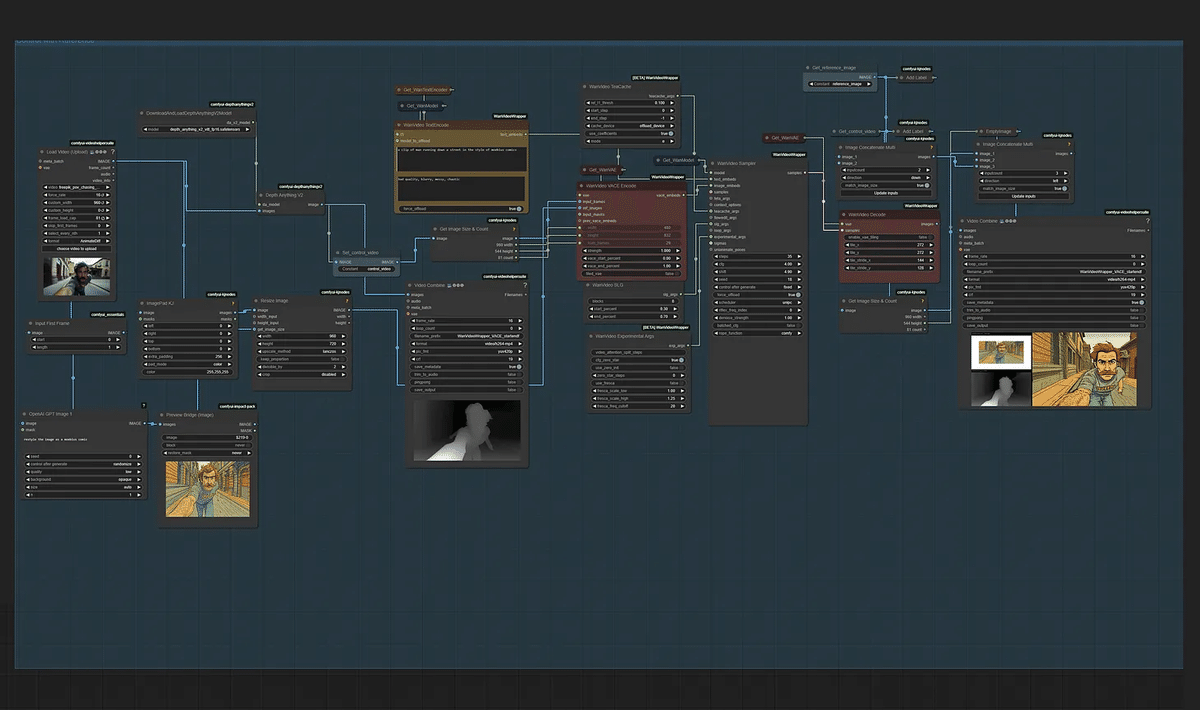
利用コストとクオリティオプション

さらに多くのモデル対応へ!