
FLUX.2 Image Generation Fastest Guide! With Google Colab Notebook


On November 25, 2025, Black Forest Labs announced FLUX.2, a next-generation image generation AI model designed for practical creative workflows.
Hello, this is Mei Soleil, the energetic yellow representative & image generation lead of AiCuty! 🌟 Today, I've got some earth-shattering news from the image generation world, so stay with me! Black Forest Labs has finally released FLUX.2, and it's not just a demo or a toy; it's designed for "practical creative workflows" that can be used for serious work. I'm super excited because it includes all the features that pros wanted, like character consistency and adherence to brand guidelines! Let's dive into the explanation! 💨
1. What Makes FLUX.2 Different! 🍌
First off, this! FLUX.2 is called "Frontier Visual Intelligence," and it can edit images at high resolutions up to 4 megapixels (4MP) while maintaining detail!

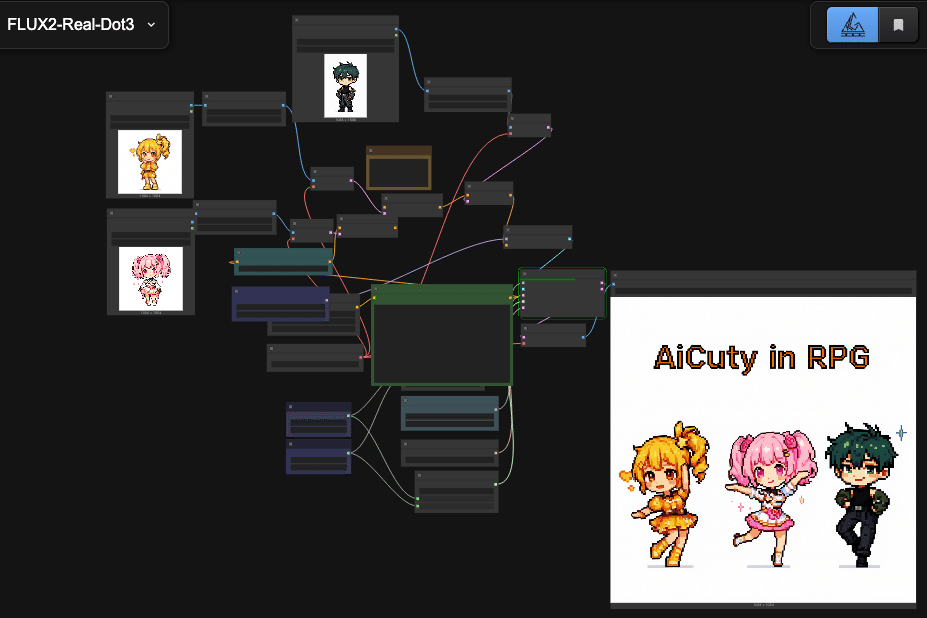
Plus, it can maintain character and style consistency even with multiple reference images, so it might be easy to draw all AiCuty members!

2. Amazing New Features ✨
Here are some new features that impressed me!
Multi-Reference Support 📸
This is revolutionary! You can reference up to 10 images at once to maintain character and product consistency!
An example of posing by loading each image!
Text Rendering 📝
Fine text in infographics, memes, and UI mockups can now be generated at a level usable in production environments!

World Knowledge 🧠
By incorporating a visual language model (VLM) called "Mistral-3 24B," it can understand real-world knowledge and spatial logic to create more plausible scenes!
 An extreme aerial panoramic view of a futuristic solar-punk city built into a giant canyon. Thousands of individual windows, flying vehicles, hanging gardens, and waterfalls are visible. In the center, a massive holographic billboard displays the text "WELCOME TO NEO-YOKOHAMA". Daytime, clear blue sky, hyper-realistic, 8k resolution, extreme detail, architectural visualization.
An extreme aerial panoramic view of a futuristic solar-punk city built into a giant canyon. Thousands of individual windows, flying vehicles, hanging gardens, and waterfalls are visible. In the center, a massive holographic billboard displays the text "WELCOME TO NEO-YOKOHAMA". Daytime, clear blue sky, hyper-realistic, 8k resolution, extreme detail, architectural visualization.
 A wide-angle shot of a busy modern coffee shop interior seen through a large circular mirror hanging on a brick wall. The reflection shows a barista making coffee, customers sitting at tables with laptops, and a menu board with legible text "TODAY'S SPECIAL". The lighting is warm and cozy. The mirror frame is rustic wood. Photorealistic, highly detailed, ray-traced reflections, coherent spatial logic.
A wide-angle shot of a busy modern coffee shop interior seen through a large circular mirror hanging on a brick wall. The reflection shows a barista making coffee, customers sitting at tables with laptops, and a menu board with legible text "TODAY'S SPECIAL". The lighting is warm and cozy. The mirror frame is rustic wood. Photorealistic, highly detailed, ray-traced reflections, coherent spatial logic.
3. Strong Lineup! 🔥
There are many models to choose from depending on the application!
- FLUX.2 [pro]: Fastest with the highest image quality! The strongest version rivaling closed models!: State-of-the-art image quality that rivals the best closed models]
- FLUX.2 [flex]: You can adjust the number of steps and is good at text description!: Take control over model parameters such as the number of steps and the guidance scale]
- FLUX.2 [dev]: 32B open-weight model! Released on Hugging Face, the strongest open model that can be run locally for non-commercial use!: 32B open-weight model, derived from the FLUX.2 base model.] weights are available on Hugging Face]
- FLUX.2 [klein]: It seems to be coming soon, and it's an open-source model with an Apache 2.0 license! (coming soon): Open-source, Apache 2.0 model]
How to Run with ComfyUI!
Everyone~! From here on, it's a bit of a maniacal "developer-oriented" corner! The FLUX.2 [dev] that was released this time is a super-huge model with 32 billion (32B) parameters! It's hard to run as is, but if you use Hugging Face's diffusers library, code is available that can be run on your strong PC (RTX 4090 recommended!)
- GPU: High-end GPUs such as RTX 4090 and RTX 5090
- Python environment: diffusers, torch, huggingface_hub, etc.
- Hugging Face Token: Access to the model is required!
Furthermore, quantized code and NVIDIA support
FLUX.2 is packed with new tools and features, including a multi-reference feature that can generate variations of dozens of similar images with photorealistic detail and cleaner fonts, even at large scales.
NVIDIA is working with Black Forest Labs and ComfyUI to make the model available at release with FP8 quantization and RTX GPU performance optimizations, reducing the VRAM required by 40% and improving performance by 40%.
FLUX.2 Dev FP8 from NVIDIA is available for both Comfy Cloud and local Comfy, reducing the VRAM requirements by 50% down to 15GB! Thanks for the great support! https://t.co/vF9gNjvOrM
— ComfyUI (@ComfyUI)
Loading tweet component...
?ref_src=twsrc%5Etfw">November 25, 2025— toyxyz (@toyxyz3)
Loading tweet component...
?ref_src=twsrc%5Etfw">November 25, 2025This is the code in the diffusers documentation to save memory and run it. Maybe this will work...!?
import torch from diffusers import Flux2Pipeline, Flux2Transformer2DModel from diffusers.utils import load_image from huggingface_hub import get_token import requests import io # Specify the model ID (lightweight with 4-bit quantization!) repo_id = "diffusers/FLUX.2-dev-bnb-4bit" device = "cuda:0" torch_dtype = torch.bfloat16 # Function to process the text encoder remotely (save memory!) def remote_text_encoder(prompts): response = requests.post( "https://remote-text-encoder-flux-2.huggingface.co/predict", json={"prompt": prompts}, headers={ "Authorization": f"Bearer {get_token()}", "Content-Type": "application/json" } ) prompt_embeds = torch.load(io.BytesIO(response.content)) return prompt_embeds.to(device) # Load the pipeline pipe = Flux2Pipeline.from_pretrained( repo_id, text_encoder=None, torch_dtype=torch_dtype ).to(device) # Set the prompt (hermit crab soda can house!) prompt = "Realistic macro photograph of a hermit crab using a soda can as its shell, partially emerging from the can, captured with sharp detail and natural colors, on a sunlit beach with soft shadows and a shallow depth of field, with blurred ocean waves in the background. The can has the text `BFL Diffusers` on it and it has a color gradient that start with #FF5733 at the top and transitions to #33FF57 at the bottom." # Execute image generation! image = pipe( prompt_embeds=remote_text_encoder(prompt), generator=torch.Generator(device=device).manual_seed(42), num_inference_steps=50, # Recommended 28-50 steps! guidance_scale=4, ).images[0] # Save image.save("flux2_output.png")⚠️ Note the License!
This FLUX.2 [dev] model has a "FLUX [dev] Non-Commercial License," so be careful! It's OK to use for personal hobbies and research purposes, or for artists to develop new workflows, but commercial use is prohibited. Non-Commercial License.] Non-Commercial License.]
If you want to use it commercially, check out the API version, FLUX.2 [pro]!
Thanks and Summary
The people at Black Forest Labs believe that "visual intelligence should be shaped not only by a few, but by researchers and creators around the world." That's why they're releasing such powerful models, which is really precious...! 🙏 FLUX.2 includes Mistral3 internally and is large, but quantization is progressing rapidly, so it sounds like the history of image generation is changing. Everyone, try it out with ComfyUI!
Featured at the AICU Lab+ ComfyJapan study session on 2025/11/26 Click here to participate in the ComfyJapan study session. Archives are also available.
#FLUX2 → Wan2.2 FLF pic.twitter.com/IWdJk1C4Yz
— AICU - つくる人をつくる (@AICUai)
Loading tweet component...
?ref_src=twsrc%5Etfw">November 26, 2025FLUX.2 still image made into a Wan2.2 FLF-Loop video is so cute!
Wan2.2 FLF-Loop video is so cute! #FLUX2 #Wan pic.twitter.com/Fr0pkCTsEq
— AICU - つくる人をつくる (@AICUai)
Loading tweet component...
?ref_src=twsrc%5Etfw">November 26, 2025The Google Colab notebook, workflow, and prompt distribution are provided beyond the paywall below!