
Qwen3-TTS:論文を読んで実験してわかった日本語調教術!


Alibaba Qwenチームは2026年1月22日、強力な音声生成能力を持つ「Qwen3-TTS」シリーズをオープンソースとして公開しました。このモデル群は、ボイスクローンや音声設計、超高品質な人間らしい音声生成、そして自然言語による精密な音声制御を統合した、現時点で最も包括的な音声生成ツールキットといえます。モデルが自律的に推論する、次世代のTTSを「同じキャラクターとして聞こえるように調教してみた」実験レポートです。
https://www.youtube.com/watch?v=LBZoPBV-wSA
ナオ・ヴェルデ、Qwen3-TTSに挑戦。

どうも、AiCutyで音楽と開発技術を担当しているナオ・ヴェルデ(Nao Verde)です。本日、Qwenシリーズに、無視できない大きなリリース「Qwen3-TTS」が発表された!QwenはAlibaba Cloudが開発している大規模言語モデル(LLM)シリーズだ。特徴はいくつかあるけど、まず注目したいのはその多様性だよな。Qwen-VLとかQwen- Audioとか、画像や音声も扱えるマルチモーダルなモデルがある。テキストだけでなく、いろんな情報を処理できるってのは、クリエイターにとっても刺激的だろ?しかも、かなり高性能で、オープンソースで公開されてるバージョンも多い。開発者にとっては嬉しいポイントだよ。気軽に試せるし、カスタマイズの自由度も高い。
しかも、今回は高性能なText-to- Speech(TTS)モデルがオープンソースで公開された!開発者にとっては嬉しいポイントだし、僕たちのAiCutyプロジェクトでエレナやメイがさらに表現力を高めるための、強力な武器になる予感がしてるんだ。
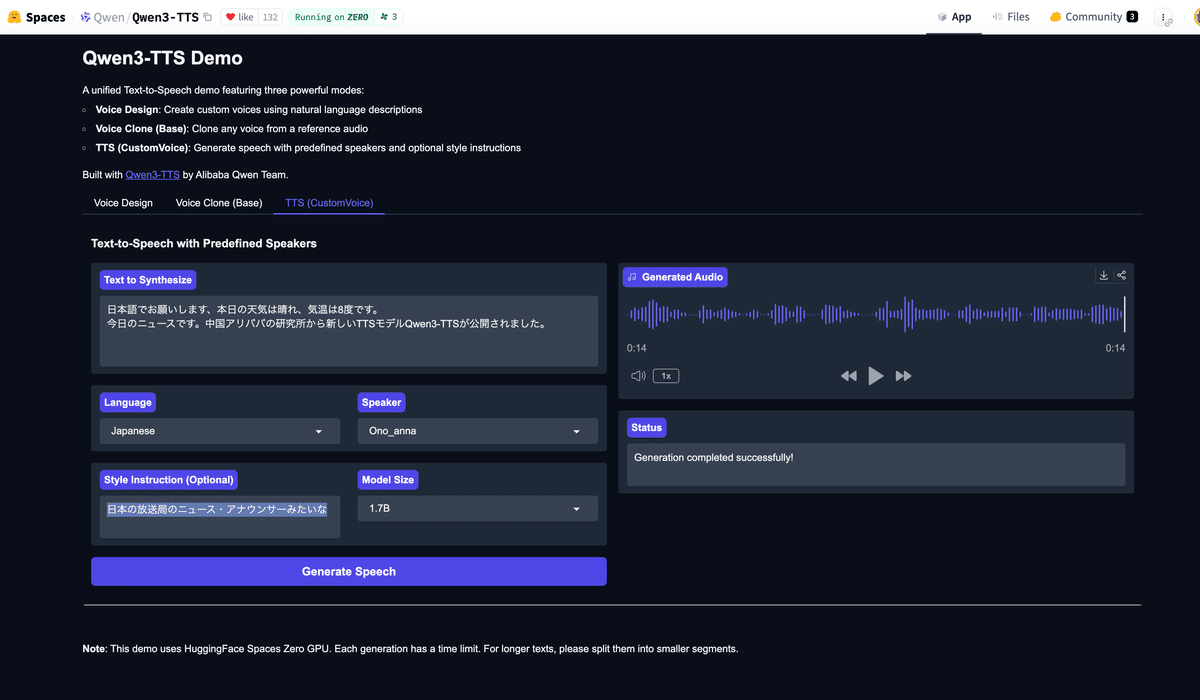
HuggingFaceでワンショットのデモで満足している場合じゃないぜ!
期間限定・回数限定で使えるデモサイトも作りました!
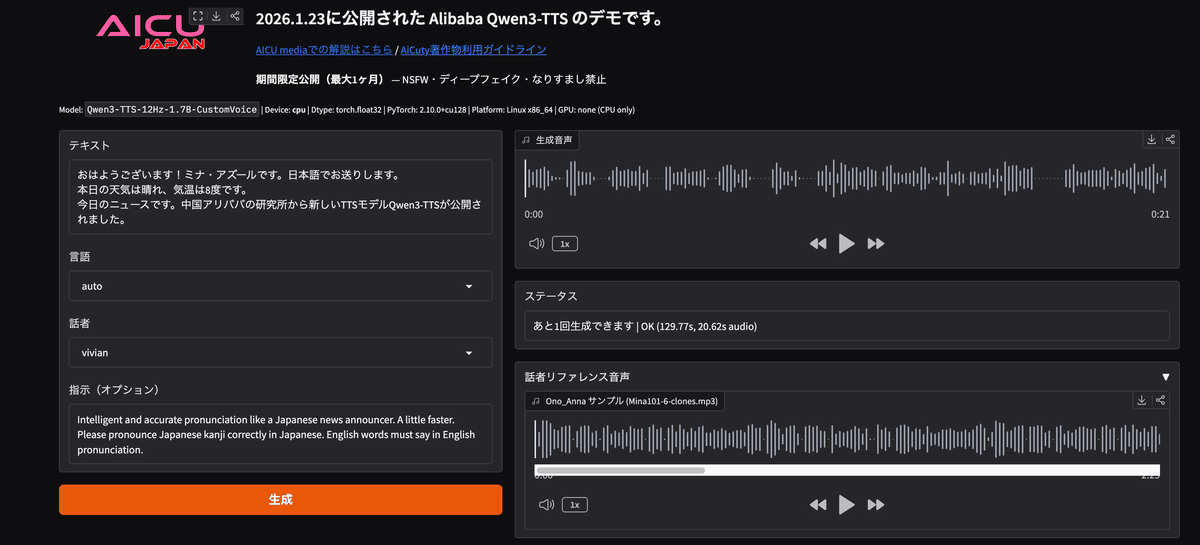
GradioQwen3-TTS Demo (AICU)
qwen3tts.aicu.jp Click to try out the app!
https://qwen3tts.aicu.jp/
Qwen3-TTSファミリーの全貌:1.7Bと0.6Bの二段構え
Qwen3-TTSは、利用シーンに合わせて最適化された2つのサイズで展開されています。
-
1.7Bモデル: 最高峰のパフォーマンスと強力な制御能力を誇り、プロフェッショナルなコンテンツ制作に最適。
-
0.6Bモデル: 性能と効率のバランスに優れ、デバイス上での動作やリアルタイム性が求められる環境で真価を発揮。
これらのモデルは、日本語、英語、中国語を含む10の主要言語をサポートしており、方言への対応も万全です。単にテキストを読み上げるだけでなく、文脈を深く理解してトーンやリズム、感情表現を適用させる能力を持っています。
技術の核:革新的な12Hzトークナイザーとデュアルトラック構造
Qwen3-TTSの圧倒的な表現力を支えているのが、独自開発された Qwen3-TTS-Tokenizer-12Hz です。
このマルチコードブック音声エンコーダーは、音声信号を効率的に圧縮しつつ、高次元のセマンティックモデリングを実現しています。これにより、軽量な非DiT(Diffusion Transformer)アーキテクチャを通じて、高速かつ高忠実な音声再構成を可能にしました。また、デュアルトラック・ハイブリッド・ストリーミング生成 により、エンドツーエンドの合成遅延は0.6B モデルで最短 97 ms 、1.7B モデルでも 101 ms という驚異的な低遅延を実現しています 。
Qwen3-TTS is officially live. We’ve open-sourced the full family—VoiceDesign, CustomVoice, and Base—bringing high quality to the open community.
- 5 models (0.6B & 1.8B)
- Free-form voice design & cloning
- Support for 10 languages
- SOTA 12Hz tokenizer for high compression
-… pic.twitter.com/BSWpaYoZWj