
Qwen3-TTS: Japanese Tuning Techniques Learned from Reading and Experimenting with the Paper!


Alibaba's Qwen team open-sourced the "Qwen3-TTS" series on January 22, 2026, which boasts powerful speech generation capabilities. This model suite is currently the most comprehensive speech generation toolkit, integrating voice cloning, voice design, ultra-high-quality human-like speech generation, and precise speech control through natural language. This is an experimental report on "training the next-generation TTS to sound like the same character" using a model that autonomously infers.
https://www.youtube.com/watch?v=LBZoPBV-wSA
Nao Verde Takes on Qwen3-TTS.

Hello, I'm Nao Verde, responsible for music and development technology at AiCuty. Today, a significant release that cannot be ignored, "Qwen3-TTS", was announced in the Qwen series! Qwen is a large language model (LLM) series developed by Alibaba Cloud. It has several features, but the first thing I want to pay attention to is its diversity. There are multimodal models like Qwen-VL and Qwen-Audio that can handle images and audio. The ability to process various information, not just text, is exciting for creators, isn't it? Moreover, it is quite high-performance, and many versions are released as open source. This is a welcome point for developers. You can try it easily and the degree of customization is high.
Moreover, this time, a high-performance Text-to-Speech (TTS) model has been released as open source! This is a welcome point for developers, and I have a feeling that it will be a powerful weapon for Elena and Mei to further enhance their expressiveness in our AiCuty project.
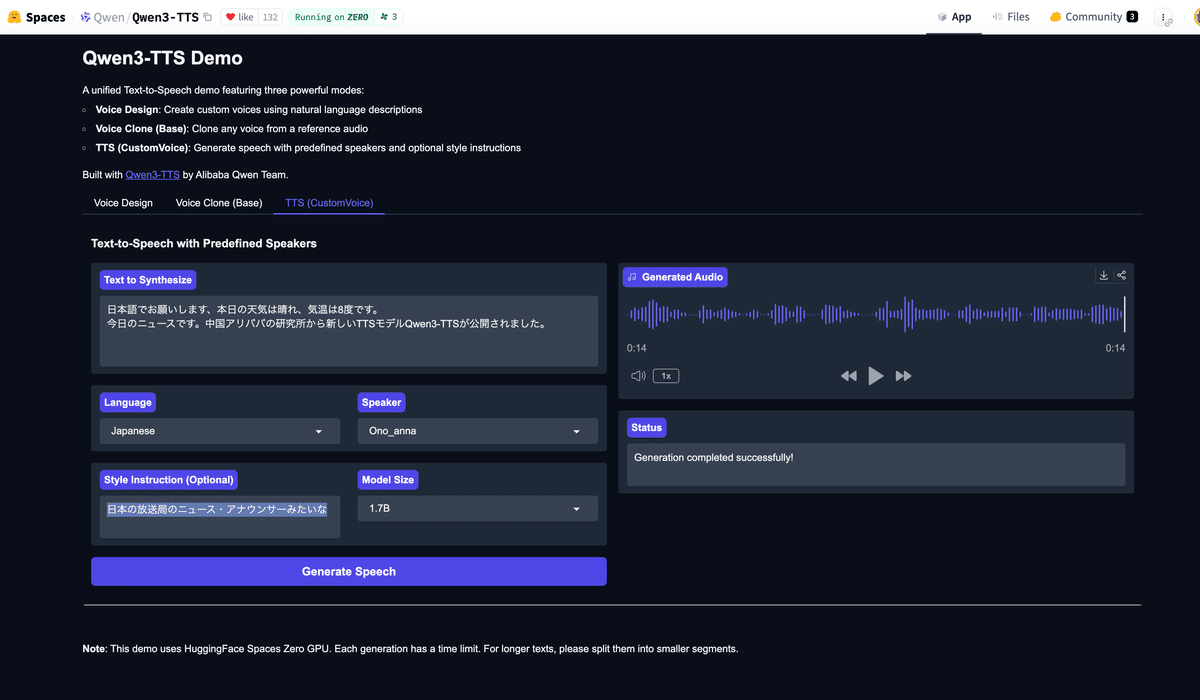
Don't be satisfied with one-shot demos on HuggingFace! We have also created a demo site that can be used for a limited time and a limited number of times!
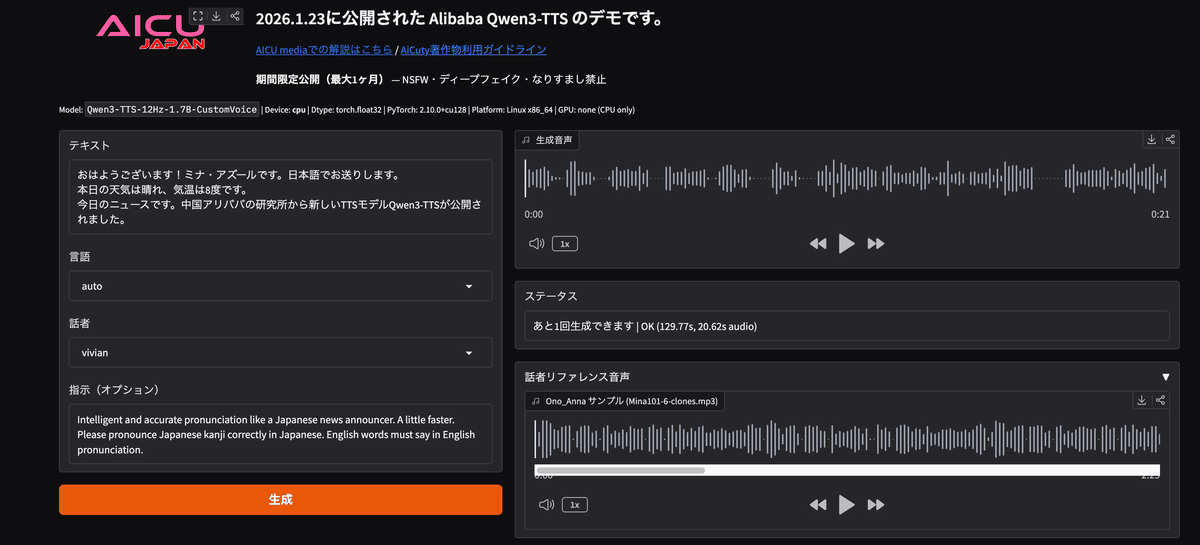
GradioQwen3-TTS Demo (AICU)
qwen3tts.aicu.jp Click to try out the app!
https://qwen3tts.aicu.jp/
The Entire Picture of the Qwen3-TTS Family: A Two-Tier Structure of 1.7B and 0.6B
Qwen3-TTS is available in two sizes optimized for different usage scenarios.
- 1.7B model: Boasts the highest performance and powerful control capabilities, making it ideal for professional content creation.
- 0.6B model: Excels in the balance between performance and efficiency, demonstrating its true value in environments where on-device operation and real-time performance are required.
These models support 10 major languages, including Japanese, English, and Chinese, and are fully compatible with dialects. They are capable of not only reading text aloud but also deeply understanding the context and applying tone, rhythm, and emotional expression.
The Core of the Technology: Innovative 12Hz Tokenizer and Dual-Track Structure
Supporting the overwhelming expressiveness of Qwen3-TTS is the uniquely developed Qwen3-TTS-Tokenizer-12Hz.
This multi-codebook audio encoder efficiently compresses audio signals while realizing high-dimensional semantic modeling. This enables fast and highly faithful audio reconstruction through a lightweight non-DiT (Diffusion Transformer) architecture. In addition, dual-track hybrid streaming generation enables end-to-end synthesis latency of as low as 97 ms for the 0.6B model and 101 ms for the 1.7B model, achieving an astonishingly low latency.
Qwen3-TTS is officially live. We’ve open-sourced the full family—VoiceDesign, CustomVoice, and Base—bringing high quality to the open community.
- 5 models (0.6B & 1.8B) - Free-form voice design & cloning - Support for 10 languages - SOTA 12Hz tokenizer for high compression -… pic.twitter.com/BSWpaYoZWj