LLM-jp-Moshi-v1 Released for Commercial Use: High-Quality Japanese Simultaneous Two-Way Voice Dialogue

Nao Verde, who is in charge of music and development for the idol project "AiCuty" created by humans and AI, will explain about a major milestone in Japanese AI research! On February 25, 2026, the Large-scale Language Model Research and Development Center (LLMC) of the National Institute of Informatics (NII) released "LLM-jp-Moshi-v1", a voice AI model that realizes simultaneous two-way (Full-duplex) dialogue in Japanese. It is worth noting that this is provided in an extremely open form with an Apache 2.0 license, which allows for commercial use.
As a result of the NII/LLMC Dialogue WG, we have released LLM-jp-Moshi-v1, a Japanese real-time voice dialogue model! It is trained using data collected independently by LLM-jp and is licensed for commercial use. See the release below for details. https://t.co/419eZGqkKW
— Ryuichiro Higashinaka (@RHigashinaka)
Loading tweet component...
?ref_src=twsrc%5Etfw">February 25, 20261. The Paradigm Shift Brought About by "Simultaneous Two-Way (Full-duplex)"
Many conventional voice dialogue systems (such as smart speakers) are "Half-duplex", that is, an interactive dialogue format in which "AI starts processing after the human finishes speaking." However, natural conversation between humans is not like that. We interject with affirmations, sometimes overlap words, and read emotions in the silent "space".
"LLM-jp-Moshi-v1" is based on "Moshi" developed by Kyutai Labs in France, and has acquired this human-like real-time responsiveness in Japanese by adding and fine-tuning dialogue data specific to Japanese. Just last year, on January 24, 2025, researchers at Nagoya University prototyped the Japanese full-duplex dialogue system "J-moshi" and released it on Hugging Face.
Technical Features
- Streaming processing: By tokenizing the voice and processing the input and output in parallel, the delay is minimized.
- Voice tokenizer "Mimi": Maintains high-quality dialogue even at low bit rates by efficiently compressing and decompressing voice information.
2. Use of Large-Scale Learning Data and ABCI 3.0
This model's accuracy is supported by a huge Japanese dialogue corpus and one of the best computing resources in Japan. Approximately 1,000 hours of diverse Japanese voice data has been input into the model's training.
- J-CHAT: Japanese small talk dialogue data.
- LLM-jp-Zoom1: Data that simulates a natural dialogue environment such as an online conference.
- Tabidachi / Japanese CallHome: Data from practical scenes such as travel guidance and telephone answering.
The computing infrastructure that learned these data is "ABCI" (AI Bridging Cloud Infrastructure), an open computing infrastructure for AI technology development and bridging, built by the National Institute of Advanced Industrial Science and Technology and operated by AIST Solutions. It was launched in August 2018 and was reborn as 3.0 in January 2025. By learning using AI Bridging Cloud (ABCI) 3.0 provided by AIST, it seems that it has learned Japanese-specific word order, intonation, and "dialogue timing."
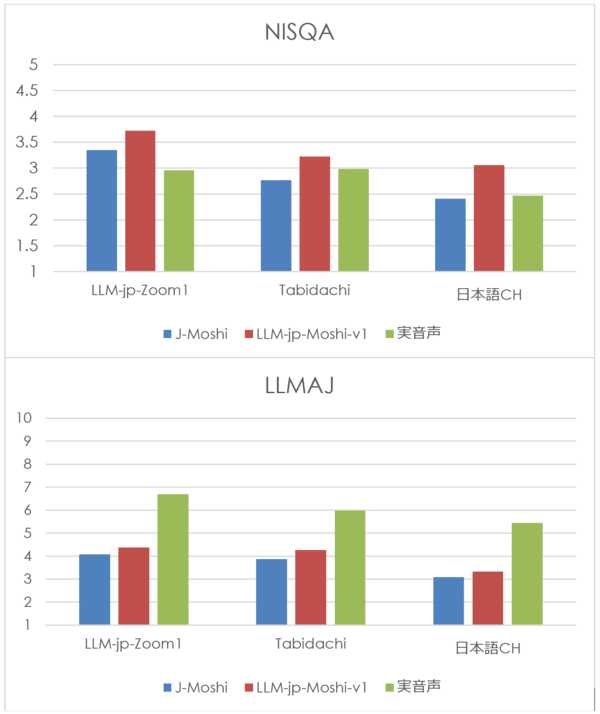
3. Improvement of "Naturalness" from Evaluation Results
The published benchmark results show significant improvements in multiple indicators compared to the existing research model (J-Moshi).
- In the dialogue continuation task (a task in which dialogue audio that is a continuation of the input audio dialogue is generated and the validity is evaluated), both objective automatic evaluation by cloud workers and subjective evaluation by humans were performed, and compared with the existing public model J-Moshi, it showed superior performance in terms of both naturalness and semantic appropriateness.
- As input audio, held-out test data of LLM-jp-Zoom1, Tabidachi (travel guidance voice dialogue), and Japanese CallHome (Japanese CH) were used. The actual audio represents the actual human-to-human audio that is a continuation of the input audio dialogue
NISQA represents the value of the automatic evaluation scale of voice (5 levels). LLMAJ is an index that represents the value (10 levels) that uses the LLM-as-a-judge framework to have a large-scale language model evaluate naturalness and fluency as dialogue. In particular, the "naturalness" score has improved significantly, indicating that it has broken away from mechanical responses and reached a level where it can provide an experience closer to the "feeling of talking to a human."
Click here to view the actual video!
4. Available from GitHub
LLM-jp-Moshi-v1
llm-jp.github.io
https://llm-jp.github.io/llm-jp-moshi/
You can interact with LLM-jp-Moshi-v1 using Kyutai's official Moshi PyTorch implementation. For details on the implementation, please refer to the original Moshi repository kyutai-labs/moshi.
- Execution requires a Linux GPU machine with 24GB or more of VRAM. MacOS is not supported.
- To avoid the model's speech echoing, please use earphones or headphones when having a dialogue instead of speakers. The audio device can be set on the browser when accessing the web UI.
License: LLM-jp-Moshi-v1 is released under the Apache License, Version 2.0.
5. Application Possibilities for Creative Business
This "Dialogue Working Group" is an academic research group established as part of the research activities of "LLM-jp", where researchers of natural language processing and computer systems gather and regularly share information about the research and development of large-scale language models. Professor Ryuichiro Higashinaka, Science Director of NII/LLMC at the National Institute of Informatics, is leading the research in close cooperation with Professor Tetsuji Ogawa of Waseda University and Associate Professor Shinnosuke Takamichi of Keio University. The emergence of this natural two-way voice dialogue model that can be used for commercial purposes has the potential to bring about evolution in various fields.
- Customer support: An advanced bot that guides customers while smoothly interjecting without interrupting them.
- Entertainment: A "live" conversation experience with game characters and virtual idols without time lag.
- Education/Counseling: Mental care and language learning where real-time response is important.
First, please listen to a small talk at a very natural speed! This "timing" technology should become an indispensable element.
Conclusion: An Open Ecosystem Creates the Future
The significance of NII releasing this model as an open Apache License, Version 2.0 is significant. This is because anyone can customize this model based on their own needs and create new services. The future of Japanese voice AI will accelerate in a more human-like and more creative direction with this new standard of "simultaneous two-way" communication.
Reference Resources
Release of commercially available simultaneous two-way Japanese voice dialogue model "LLM-jp-Moshi-v1" - National Institute of Informatics
www.nii.ac.jp The National Institute of Informatics is the only academic research institute in Japan that aims to create future value in the new research field of informatics.
https://www.nii.ac.jp/news/release/2026/0225.html